Горячие JEP'ы 25 -- юбилейное @ Joker 2025 2025-10-17
16 сентября состоялся релиз Java 25, и по традиции JPoint и Joker мы детально разобрали все ключевые изменения.
Какие нововведения ждут разработчиков? Какие JEP окажут влияние на повседневное написание кода? Разобрались, какие улучшения внесены в язык и платформу, на что стоит обратить внимание в первую очередь и какие изменения вышли в юбилейной LTS-версии Java. Посмотрели на эволюцию языка и обсудили, как эти новшества могут повлиять на наш код и какие инструменты помогут быстрее адаптироваться к изменениям.
RetweetJava 24. Горячие JEP'ы @ JPoint 2025 2025-04-04
18 марта состоялся релиз Java 24, и, по традиции JPoint/Joker, мы детально разобрали все ключевые изменения. Какие нововведения ждут разработчиков? Какие JEP окажут влияние на повседневное написание кода? Разобрались, какие улучшения внесены в язык и платформу, на что стоит обратить внимание в первую очередь и какие изменения подготовят нас к будущей юбилейной LTS-версии Java. Посмотрели на эволюцию языка и обсудили, как эти новшества могут повлиять на наш код и какие инструменты помогут быстрее адаптироваться к изменениям.
RetweetJava 23. Горячие JEP'ы @ Joker 2024 2024-10-09
Поговорили про новый релиз Java 23: какие JEP повлияют на каждодневное написание кода, какой API изменился, а какие JEP прошли дальше без изменений — и чего ждать в будущем.
RetweetАсинхронный транспорт Cassandra @ HighLoad++ 2022 2022-11-24
Выступил с докладом "Асинхронный транспорт Cassandra" на HighLoad++ 2022.
Cassandra является основным хранилищем (мета)данных в Одноклассниках. У нас развёрнуты сотни высоконагруженных кластеров из сотен узлов и тысяч клиентов, распределённых по нескольким дата-центрам. Мы используем и активно развиваем собственный форк Cassandra 2.x. Помимо фиксов множества багов и многочисленных оптимизаций, мы реализовали глобальные индексы (которые работают), поддержали партиционированные транзакции (NewSQL), полностью автоматизировали эксплуатацию в production и многое другое. Но в этом докладе мы сконцентрируемся на подходе FatClient, который используется в наших системах повсеместно.
Подход FatClient переносит роль координатора запросов на клиента, который становится полноценным участником кластера Cassandra. Это позволяет устранить лишние сетевые задержки, разгрузить ноды Cassandra от сетевых задач координации и значительно повысить производительность и стабильность поведения всей системы. Но несмотря на все достоинства подхода, мы столкнулись с неэффективностью и ограничениями существующего транспорта Cassandra на масштабах кластеров, состоящих из тысяч участников: узлов, хранящих данные, и клиентов, работающих с этими данными.
В докладе мы подробно рассмотрим собственную реализацию асинхронного транспорта Cassandra, которая позволила нам существенно сэкономить ресурсы и упростить жизнь разработчиков. Новый транспорт основан исключительно на Java SDK и лаконичной, но эффективной реализации Actor Model. Помимо устройства нашего решения, поговорим про различные оптимизации, возникшие по пути проблемы, а также переключение на асинхронный транспорт нагруженных кластеров Cassandra в production.
RetweetАсинхронный транспорт Cassandra @ Joker 2022 2022-11-19
Выступил с докладом "Асинхронный транспорт Cassandra" на Joker 2022.
Cassandra является основным хранилищем (мета)данных в Одноклассниках. У нас развёрнуты сотни высоконагруженных кластеров из сотен узлов и тысяч клиентов, распределённых по нескольким дата-центрам. Мы используем и активно развиваем собственный форк Cassandra 2.x. Помимо фиксов множества багов и многочисленных оптимизаций, мы реализовали глобальные индексы (которые работают), поддержали партиционированные транзакции (NewSQL), полностью автоматизировали эксплуатацию в production и многое другое. Но в этом докладе мы сконцентрируемся на подходе FatClient, который используется в наших системах повсеместно.
Подход FatClient переносит роль координатора запросов на клиента, который становится полноценным участником кластера Cassandra. Это позволяет устранить лишние сетевые задержки, разгрузить ноды Cassandra от сетевых задач координации и значительно повысить производительность и стабильность поведения всей системы. Но несмотря на все достоинства подхода, мы столкнулись с неэффективностью и ограничениями существующего транспорта Cassandra на масштабах кластеров, состоящих из тысяч участников: узлов, хранящих данные, и клиентов, работающих с этими данными.
В докладе мы подробно рассмотрим собственную реализацию асинхронного транспорта Cassandra, которая позволила нам существенно сэкономить ресурсы и упростить жизнь разработчиков. Новый транспорт основан исключительно на Java SDK и лаконичной, но эффективной реализации Actor Model. Помимо устройства нашего решения, поговорим про различные оптимизации, возникшие по пути проблемы, а также переключение на асинхронный транспорт нагруженных кластеров Cassandra в production.
Опыт и идеи, представленные в докладе, могут быть полезны как сетевым разработчикам, так и разработчикам высоконагруженных распределённых систем на Java.
RetweetИнтервью с Иваном Буймовым и Алексеем Учакиным 2022-10-27
Пообщались с Иваном Буймовым и Алексеем Учакиным в главной студии конференции DevOops 2022. Прямой эфир с офлайн-площадки DevOops: настоящее и будущее DevOps, впечатления от конференции и подробности, не вошедшие в доклады.
RetweetOK S3 @ Saint Highload++ 2022 2022-09-23
Выступил с докладом "OK S3" на Saint Highload++ 2022.
Одноклассники уже длительное время эксплуатируют собственные распределённые отказоустойчивые хранилища данных. Для хранения и обработки почти эксабайта бинарных данных (видео, фото, музыка и др.) используются one-blob-storage и one-cold-storage. В качестве транзакционных хранилищ развёрнуты десятки нагруженных кластеров NewSQL на базе Cassandra, распределённых по трём или пяти дата-центрам. Мы успешно переживаем аварии вплоть до выхода из строя дата-центра без деградации обслуживания, в том числе в час пик.
Помимо своих систем, мы эксплуатируем множество готовых продуктов для хранения артефактов сборки и тестирования, библиотек, образов, пакетов, логов, бэкапов и т.д. Единственным общим знаменателем в качестве подключаемого бэкенда хранения для всех этих сервисов является Amazon S3. S3 предоставляет высокоуровневый API для работы с объектами, а также обладает развитой экосистемой инструментов и SDK для многих языков.
Мы рассмотрим реализацию совместимого с S3 сервиса в Одноклассниках поверх уже существующих NewSQL и хранилища блобов: архитектуру и схему данных, особенности и компромиссы, оптимизации и производительность, а также встреченные по пути сложности и неожиданности.
RetweetИнтервью с Димой Ивановым и Лёшей Фёдоровым 2022-06-26
Пообщались с Димой Ивановым и Лёшей Фёдоровым в главной студии конференции Hydra/C++ Russia 2022.
RetweetOK S3 @ Hydra 2022 2022-06-26
Выступил с докладом "OK S3" на Hydra/C++ Russia 2022.
Odnoklassniki team has been developing and maintaining distributed fault-tolerant custom storages for many years. Our hot/cold blob storages provides efficient handling and processing of binary data (video, photo, music, etc.) approaching 1EB in size. Cassandra-based NewSQL supports our transactional workloads in numerous high-performance distributed clusters.
Apart from custom homemade systems we have been using a fleet of deployed on-premises external products to store and deliver build and test artifacts, libraries, images, packages, logs, backups, etc. External Amazon S3 or on-premises S3 compatible storage service may fit the role of the common storage backend for all those products. S3 provides a high level object API and an evolved ecosystem of tools and SDKs for the most popular languages and platforms.
In his talk Vadim will describe implementation of S3 compatible storage service based on battle-tested blob and NewSQL storages at Odnoklassniki. The talk will cover the architecture and data model, features and trade-offs, performance and optimization, some intricacies and surprises.
The ideas and experience presented in the talk might be useful to designers and developers of distributed storage services, especially S3-compatible and/or Cassandra-based ones.
RetweetКоманда WinterMUTE @ ICFPContest 2021 2021-07-12

9-12 июля 2021 года прошёл очередной ICFPContest, в котором наша команда WinterMUTE снова приняла участие.
См. наши отчёты о предшествующих ICFPContest 2020, ICFPContest 2019 и ICFPContest 2018.
Задача
За две недели до начала контеста в твиттере организаторов появился анонс:
Slightly less than two weeks until ICFP Contest 2021 starts! We're looking forward to seeing some old friends again this year!

А за несколько дней до начала контеста организаторы опубликовали загадочный спойлер:

Суть его стала понятна уже после публикации лаконичной спецификации на старте контеста, из которой следовало, что участники (а точнее, их решения) будут играть в популярное в Японии развлечение Human Tetris.

Входными данными для решения каждой проблемы были:
- Полигон "дыры" в виде набора целочисленных координат (не меньше трёх точек)
- Целочисленные координаты вершин фигуры (не меньше двух точек)
- Рёбра фигуры в виде пар номеров вершин
- Допустимое изменения квадрата длины ребра фигуры (epsilon)
В качестве решения отправлялись целочисленные координаты вершин трансформированной фигуры.
Решение (поза) считалось корректным при выполнении следующих условий:
- Все рёбра фигуры в наличии
- Изменение длин рёбер удовлетворяет ограничению epsilon
- Точки всех рёбер находятся внутри дыры или проходят по её границе
Далее для каждого корректного решения вычислялись "дизлайки" как сумма квадратов расстояний от каждого вершины дыры до ближайшей вершины трансформированной фигуры. Иными словами, меньше дизлайков получали решения, которые покрывали бОльшую часть дыры, оставаясь в её пределах.
На основе вычисленных дизлайков решения, а также минимальных дизлайков среди всех решений других команд и размерности решаемой проблемы вычислялась оценка отправленного решения:

Взаимодействие участников и организаторов осуществлялось через простой HTTP API: получение JSON с описанием проблемы, отправка JSON с решением.
Наконец, организаторы заранее предупредили о расписании последующих апдейтов спецификации и публикации новых проблем через 12, 24, 36 и 48 часов.
Кстати, вот пример проблемы (и наш старый друг):

Команда
Как и в прошлом году во-многом из-за COVID-19 все взаимодействовали удалённо. Команда была распределённой, но в рамках всего нескольких часовых поясов.
Вначале для коммуникации мы планировали использовать сервис Gather, но из-за требовательности к ресурсам откатились на проверенный Google Meet, где практически нонстопом все сидели с видео и звуком.
Команда на этот раз была компактной, вот эти ребята:
- Андрей Власовских (JetBrains) -- нулевой и часть первого дня
- Антон Волохов (Apple)
- Вадим Цесько (Одноклассники)
- Олег Шпынов (JetBrains Research)
Решение
Перед соревнованием мы решили, что наибольшим общим знаменателем для большинства участников остаётся Java, но всё равно практически сразу втащили в дополнение к Java язык Kotlin (и регулярно фрустрировались от скорости его компиляции).
Day 0
Когда прочитали спеку и поняли, что взаимодействовать с организаторами будем через API, а паковать свой код и отправлять его никуда не будет нужно, решили быстро перейти с Ant (где это всё у нас уже было реализовано) на Gradle. Чтобы было интерактивнее, попробовали кодить вместе через Code With Me, но отказались от этой идеи, когда осознали, что код, который одновременно редактируют несколько человек, почти никогда не компилируется. В итоге стали работать по-старому: через пуши в одну ветку без всякого code review и голосовые анонсы с изменениями и просьбами их подтянуть к себе.
Сперва занялись обязательными задачами. Я втащил Gradle. Антон взялся за модель предметной области и её (де)сериализацию. Андрей запилил клиента к API, выкачал и распарсил все доступные проблемы.
Возникло обоснованное подозрение, что задача в общем случае алгоритмически неразрешима и для лучшего понимания различных крайних случаев можно начать с разнообразных тактик модификации фигур. Фактически задачу можно свести к поиску оптимального решения системы нелинейных уравнений, т.е. нахождению целочисленных координат фигуры, которые удовлетворяют ряду ограничений: сохранение длин рёбер в допустимых пределах и нахождение всех рёбер в дыре -- а также минимизируют дизлайки, но к этому мы ещё вернёмся.
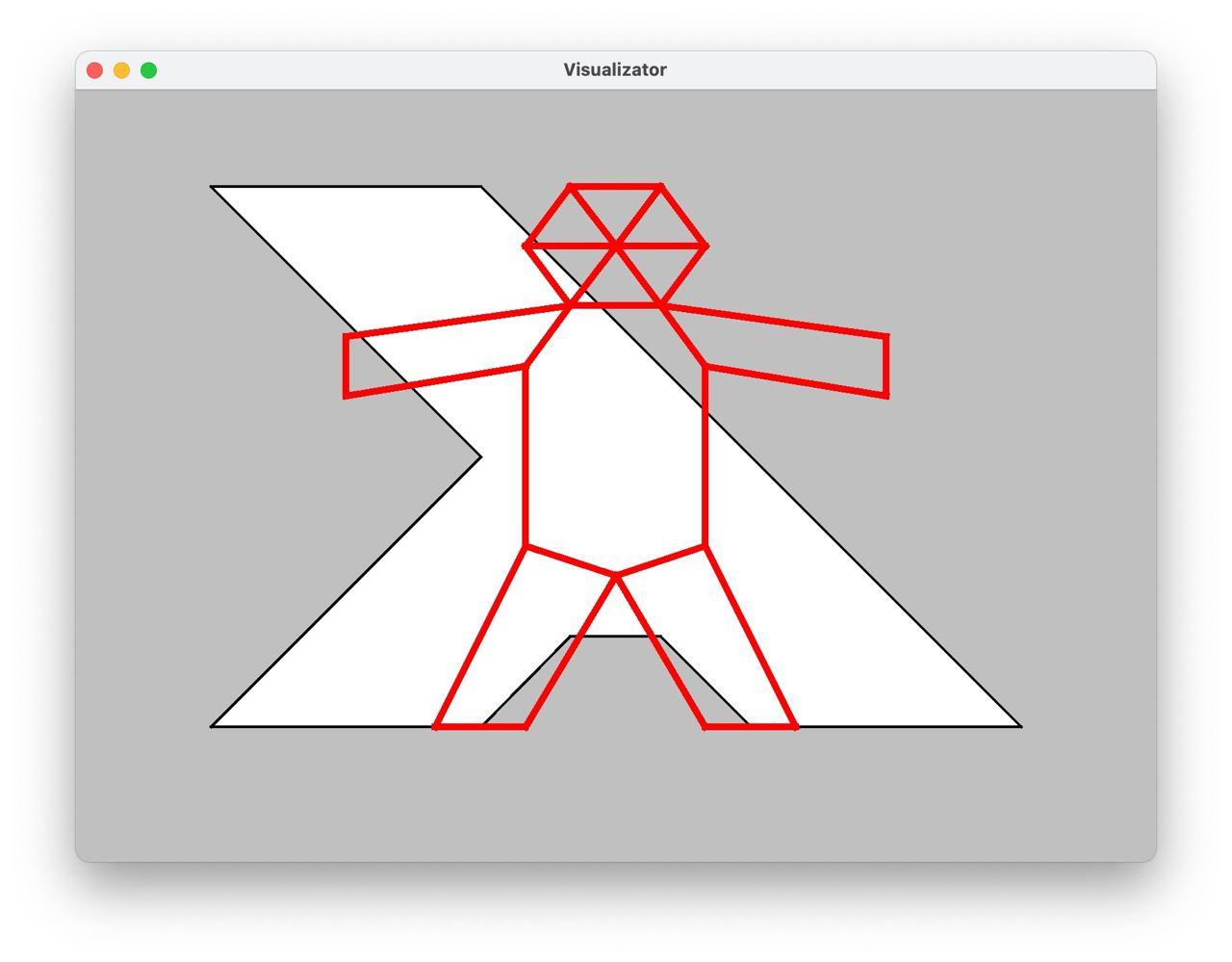
Олег начал пилить ламповый графический клиент (далее UI), без которого в текущем контесте было никуда. На Kotlin.
UI позволял отображать дыру и текущую позу, модифицировать позу через простой интерфейс Action, а также проверять различные инварианты: попадание в дыру, допустимое растягивание/сжатие рёбер и многое другое -- но об этом дальше, а пока UI выглядел так:
Андрей реализовал базовые MoveAction и RotateAction на основе афинных преобразований Java AWT, а также проверку, что поза находится в дыре.
Олег интегрировал их в UI и продолжил наращивать функциональность нашего главного интерфейса.
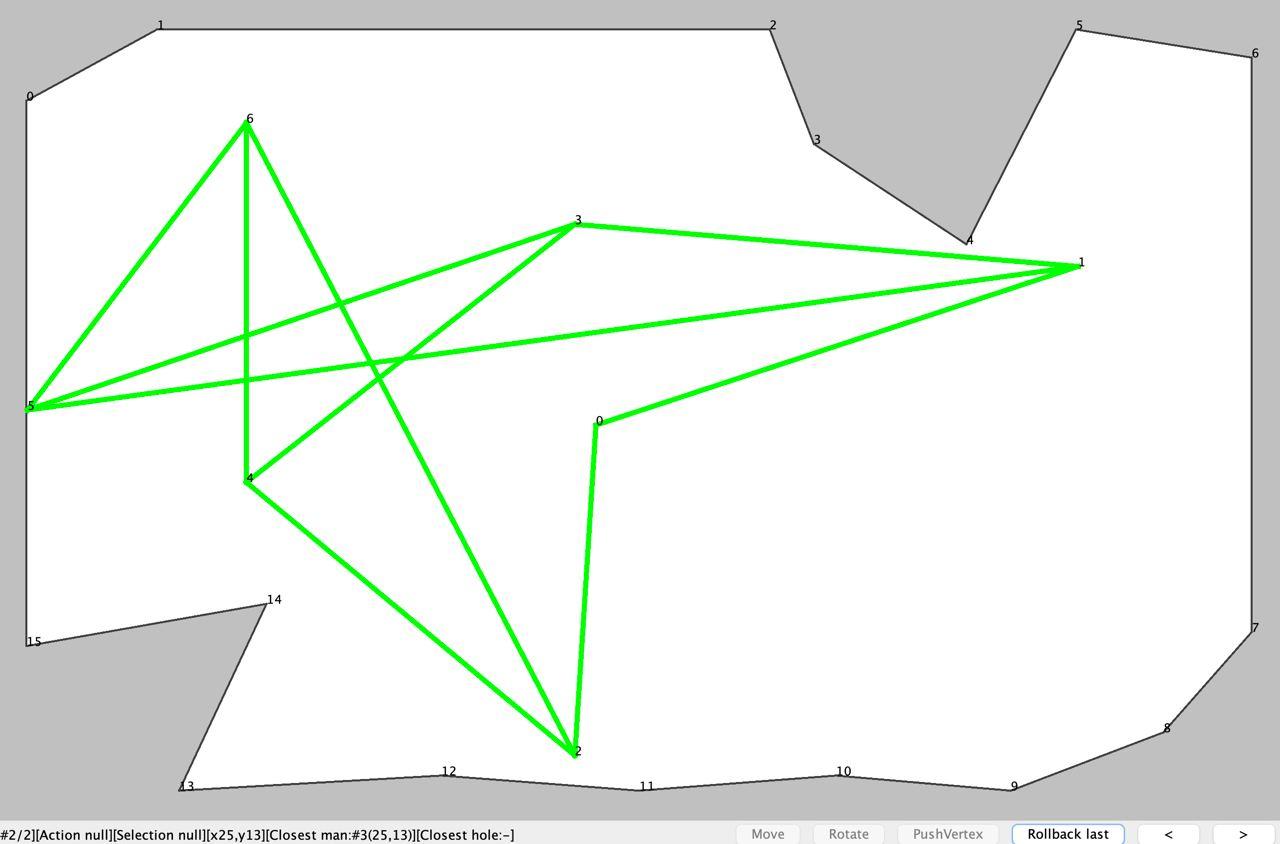
Я загорелся идеей реализовать PushAction, который позволит оттягивать/заталкивать вершины фигуры с сохранением соотношений ребёр (как будто мы толкаем вершины модели на шарнирах), и начал придумывать прототип:

Через некоторое время стало понятно, что перемещение интересующей вершины в указанную пользователем точку с последующим поиском координат всех других вершин, удовлетворяющих топологии модели -- это практически та же задача, которую мы пытаемся решить изначально.
Т.е. наивная реализация PushAction могла работать только в простейших случаях перемещения сегмента из отрезков.
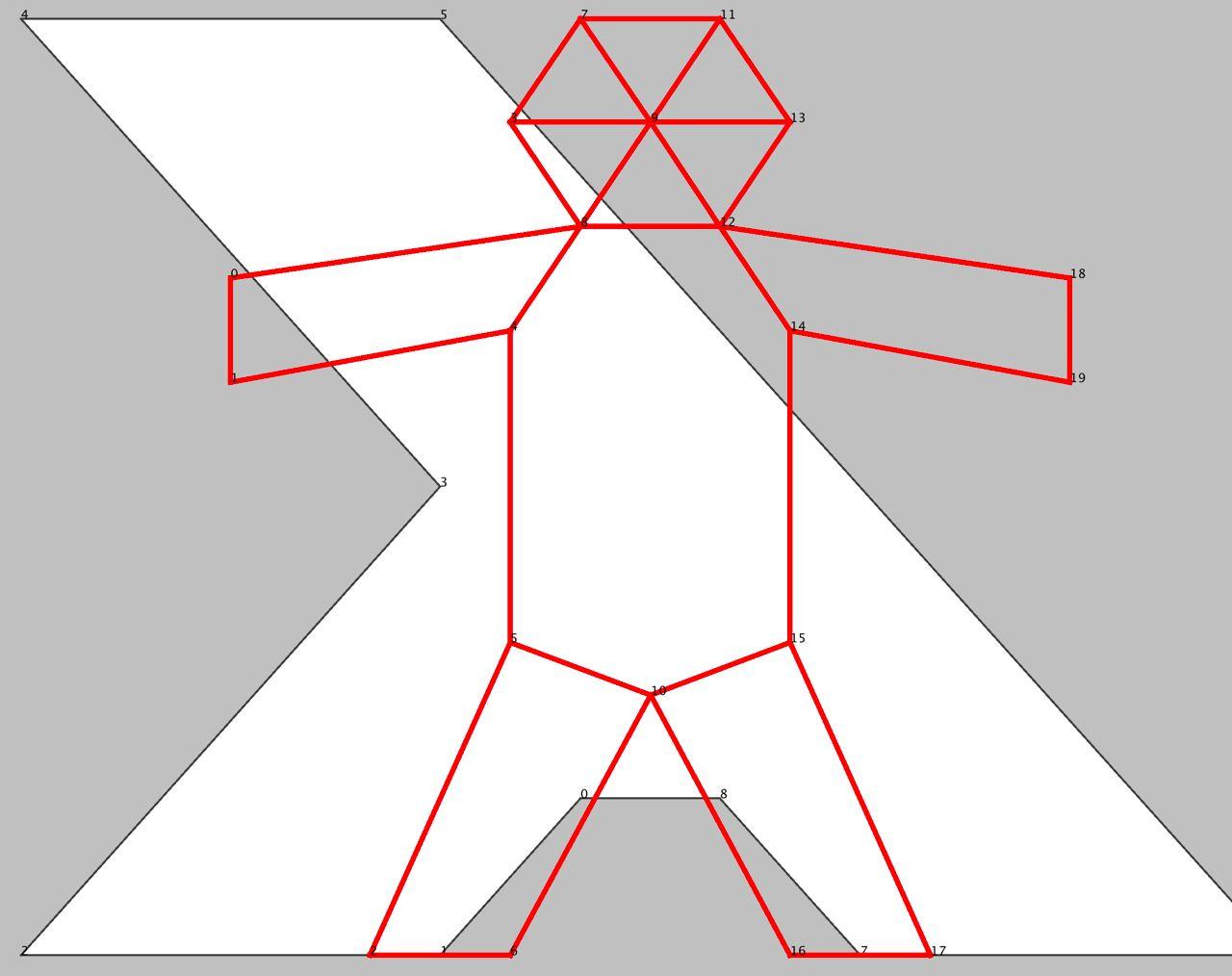
Дело шло к ночи нулевого дня, но Олег не останавливался, реализовал проигрывание модификаций позы вперёд/назад во времени и подсвечивание цветами проблемных вершин:
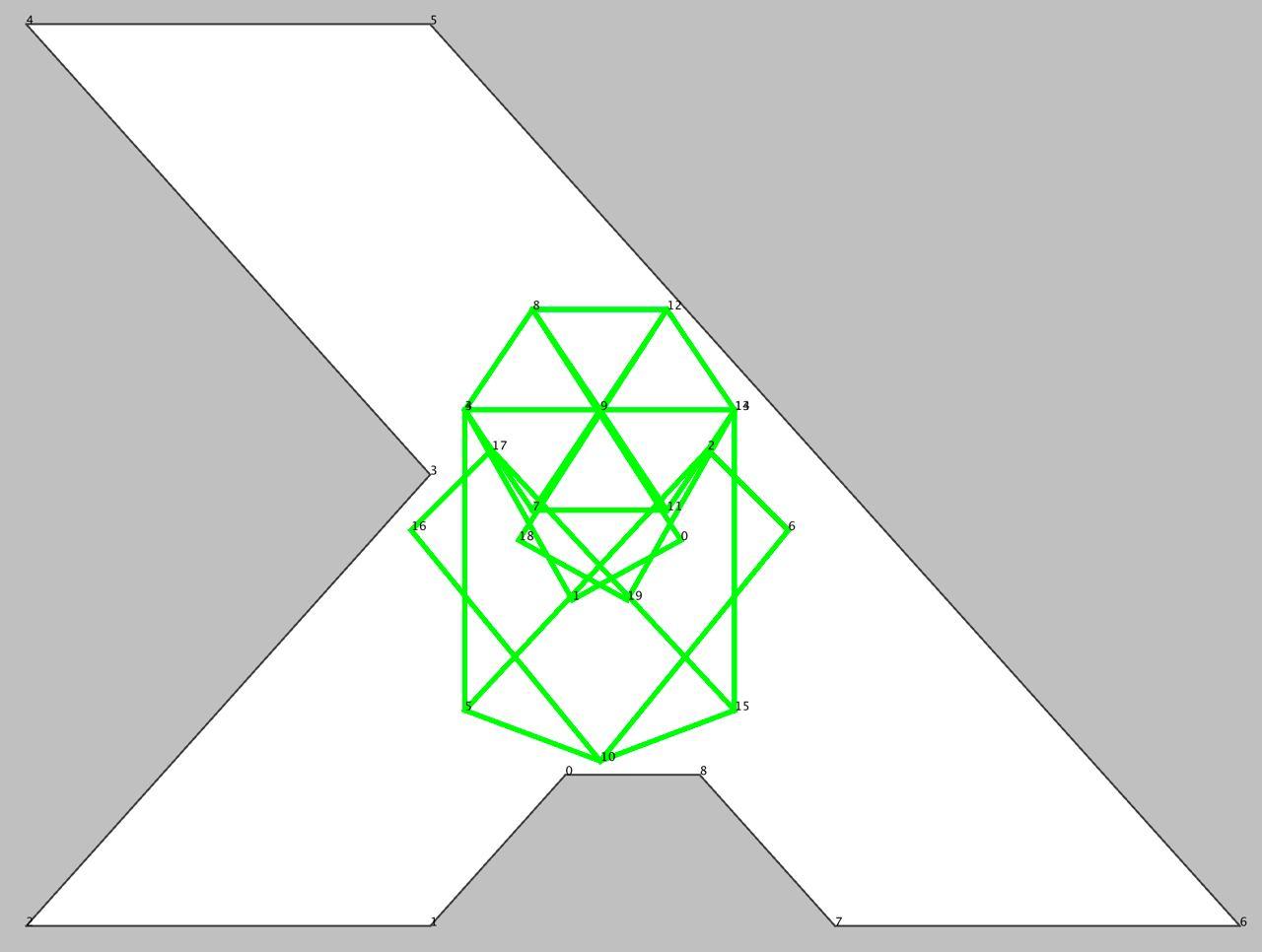
Все ушли спать, но не Антон, который запилил FoldAction: он позволял складывать позу вдоль указанного отрезка в указанном направлении (как показала практика, наш основной боевой инструмент):
Day 1
Наступил следующий день.
FoldAction Антона и бурное развитие UI произвели фурор.
Андрей помогал с реализацией геометрии средствами Java AWT.
Олег переключился на геометрию, реализовал расчёт и отображение выпуклой оболочки, центрирование позы и дыры, а также AutoRotateAction, который совмещал основные направления позы и дыры:
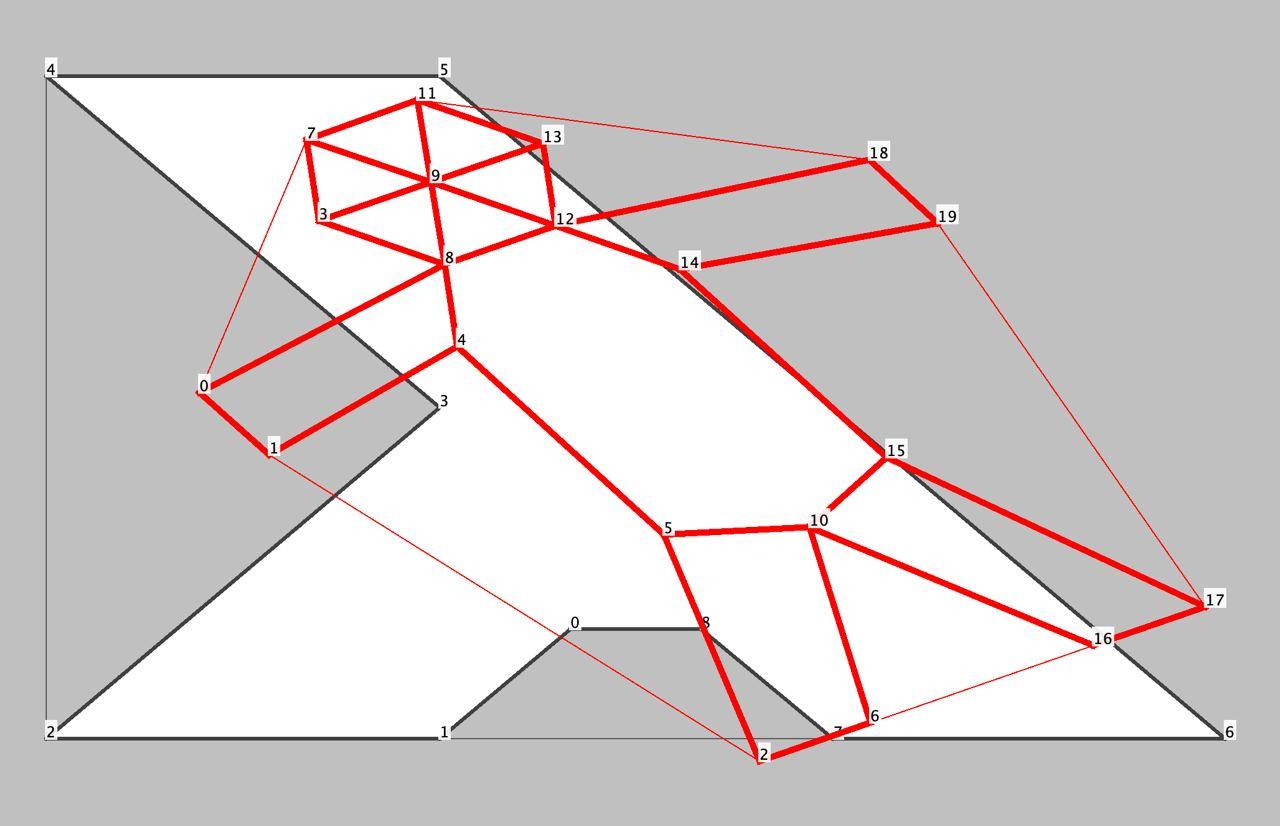
После этого Олег реализовал AutoFoldAction, который использовал примитив Антона и пытался сворачивать позу, пока уменьшалась площадь её выпуклой оболочки.
Я на тот момент ещё не отказался от PushAction и пытался его доработать без значительного усложнения, но имеющиеся проблемы не позволяли его использовать, несмотря на возлагаемые надежды.
Антон реализовал отправку решений -- дело шло к окончанию Lightning Round (первые сутки контекста).
Очень хотелось что-то уже нарешать и отправить, поэтому Олег реализовал первую стратегию автоматического решения задач AutoKutuzoffStrategy. Она комбинировала реализованные к данному моменту Actionы: AutoFoldAction, смещения и повороты -- пытаясь, преобразовать и запихнуть фигуру в дырку.
И тут нас ждала первая засада.
Дело в том, что все координаты в постановке задачи и принимаемых решениях целочисленные, а мы всё считали в double.
Но нельзя так просто взять и округлить double-координаты вершин, не изменив длины смежных рёбер (если вершина и так уже не находится в целых координатах).
С учётом того, что граф фигуры связан, возникает каскадный эффект.
До этого момента мы почему-то считали, что epsilon это просто хак, чтобы позволить участникам всё считать в double, а затем спокойно округлять.
Но оказалось, что epsilon это жёсткое ограничение пространства валидных вариантов в условиях целочисленности координат.
Антон занялся этой проблемой и запилил PosifyAction, который берёт каждую вершину с double-координатами и пытается округлить её так (комбинации ceil()/floor для x/y), чтобы не нарушить ограничения на длины всех рёбер (с учётом epsilon).
Олег допилил и зафиксил AutoFoldAction, потому что в общем случае фигуру можно согнуть не по произвольному отрезку.
В итоге мы даже что-то отправили в Lightning Round, но эти решения оказались невалидными, и тут мы поняли (в очередной раз), что надо работать над собственной валидацией решений перед отправкой.
Кстати, организаторы и в этот раз подумали о brute force, поэтому решение каждой проблемы можно было присылать не чаще, чем раз в 5 минут.
Тем временем Lightning Round закончился, и было опубликовано обновление спеки: проблемы (и старые тоже) могли содержать бонусы, которые можно было взять, если поставить вершину своей позы на указанную точку, а затем эти бонусы можно было использовать, но уже при решении других проблем. Именно эти бонусы отмечены цветными кругами на приведённых примерах проблем. Мы решили не заниматься бонусами, пока не научимся хорошо решать основную задачу.
Обложили все Actionы проверками, чтобы вылавливать тех, кто трансформирует позу с поломкой ограничений, и остаток дня занимались вылавливанием и фиксом багов.
Day 2
Олег выделил отдельную эвристику WiggleAction, которая пыталась потеребить позу в небольших пределах с надеждой, что она влезет в дыру, а затем подключился к проблеме округлений и запилил сетку и функции отладки в UI:
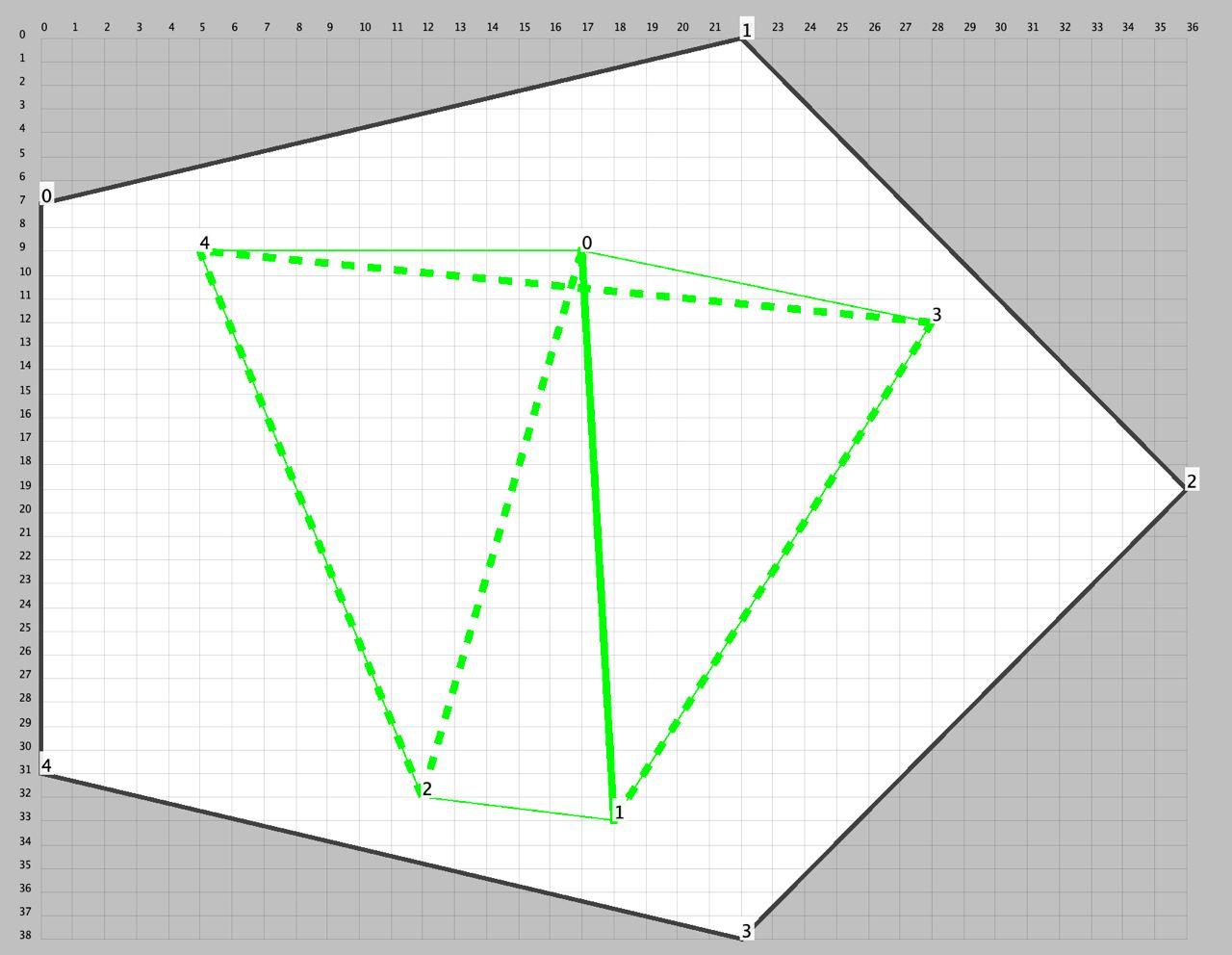
Отладка положения вершин с перемещением по целым числам показала, что это не всегда возможно, и если что-то двигать при трансформации позы, то рёбра целиком.
Но и тут некоторые варианты после FoldAction и RotateAction оказывались несовместными.
Стало понятно, что проблема с epsilon гораздо серьёзнее, чем мы думали.
Я тоже не мог пройти мимо и реализовал предварительное смещение всей позы целиком для уменьшения дробной части в координатах всех вершин (в среднем), чтобы хоть как-то помочь PosifyAction, который лечил каждую отдельно взятую вершину, но мог покалечить смежные.
К этому моменту какие-то проблемы у нас решались, отправленные решения принимались, но возникло отчётливое понимание, что нам нужна не эволюция, а революция и драйв. И тут понеслось...
У меня в очередной раз засвербило, наконец, попробовать формализовать задачу и попробовать какой-нибудь Solver. Я полистал tutorialы, набросал транслятор проблемы в систему уравнений в виде модели SMT 2, натравил Z3 Prover и о чудо! Solver выдал нам автоматически найденное решение проблемы #11:
$ time z3 011.smt
sat
(
(define-fun v0y () Int
0)
(define-fun v1y () Int
10)
(define-fun v1x () Int
10)
(define-fun v2x () Int
0)
(define-fun v0x () Int
10)
(define-fun v2y () Int
10)
(define-fun h0y () Int
0)
(define-fun h0x () Int
10)
(define-fun h1y () Int
10)
(define-fun h2x () Int
0)
(define-fun h1x () Int
10)
(define-fun h2y () Int
10)
)
real 0m0.666s
user 0m0.628s
sys 0m0.000sПроблема #11 выглядит одной из самых простых и была выбрана для простоты отладки генерации SMT, а существующие эвристические стратегии с ней пока не справлялись:

Так у нас вечером предпоследнего дня появилась ещё одна SolverStrategy, которая запускала Z3 внешним процессом и, если решения не было через минуту, убивала его.
Какое-то время было потрачено на попытки втащить Java-биндинги к Z3, но они все увенчались провалом: то артефакты без POM, то недостающие зависимости, то ещё что-то.
Ещё какое-то время ушло на эксперименты с Google OR-Tools, но проект до сих пор не Maven-изирован, кроме того, по результатам беглого просмотра документации и примеров не было очевидно, что удастся выразить и решить систему квадратичных уравнений. Но это не точно.
Всё это не было бы возможно без помощи Олега, который параллельно реализовал нарезание дыры на треугольники, что было необходимо для формирования ограничений на расположение вершин в виде наборах SMT assertов, а затем реализовал автоматическое извлечение запрещённых треугольников из выпуклой оболочки дыры -- исходные данные для ещё одного набора ограничений на расположение рёбер позы.
В итоге SolverStrategy удалось решить несколько (всего, но хоть что-то) задач, с которыми не справлялась KutuzoffStrategy (которая работала на AutoFoldAction).
Тем временем Антон упоролся по полной...
Он подхватил брошенную идею с PushAction, разобрался, погрузился и втащил в наш проект сторонний физический движок, который позволил сделать именно то, о чём мы мечтали все эти три дня:
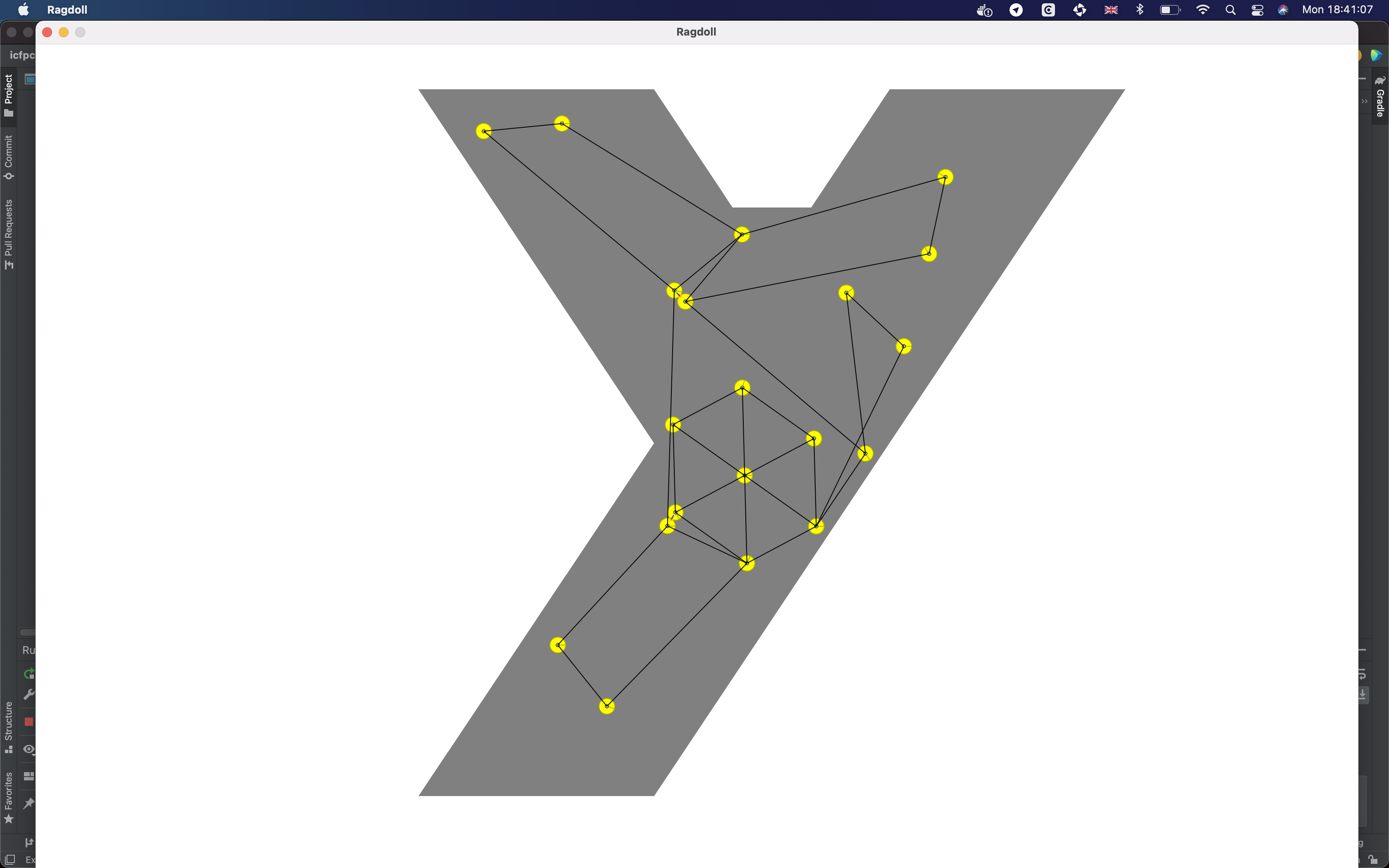
Можно хватать и тащить за любые вершины и граф динамически перестраивается с сохранением инвариантов. С ходу Антон успешно заслал ручные решения для нескольких тяжёлых проблем, которые были не по зубам ни одной из существующих стратегий, но до автоматического применения эту модель мы, к сожалению, довести уже не успели.
Впрочем, на задачах с маленьким epsilon (строгим ограничением на длину рёбер) возникали определённые проблемы: приходилось многократно теребить вершины, чтобы получить валидное решение.
Day 3
К концу контеста кода (не тестов) становилось всё больше, а с ростом объёма кода увеличивалось и количество багов.
Антон заметил, что некоторые валидные решения мы считали невалидными и наоборот валидные на наш взгляд решения не принимались организаторами.
Олег ловким движением перевёл валидацию решения на проверку ограничений на треугольники дыры по аналогии с SolverStrategy -- наступила тотальная консистентность.
Оставшиеся часы до окончания контеста мы провели в оптимизациях и прогоне различных стратегий на всех имеющихся вычислительных ресурсах, чтобы окончательно обсчитать проблемы со всеми фиксами и отправить успешные решения.
В последний час я внезапно вспомнил, что наша SolverStrategy не принимает во внимание epsilon, т.е. ищет координаты вершин позы, которые сохраняют длины рёбер строго неизменными, хотя в большинстве проблем допустимо растяжение/сжатие в определённых пределах.
И это ведь сильно сужает пространство решений, верно?
Мы тоже так решили. Я наспех ослабил ограничения на длины рёбер в уравнениях SMT с точностью до epsilon и... Solver теперь за разумное время решает только примитивную проблему #11. Может быть, свобода это не всегда благо?
Итоги
Судя по Scoreboard, команда WinterMUTE вошла в ТОП100 (100-е место из 160). Скромный результат...
Но вся команда получила море фана, а лично я закрыл гештальт по применению SMT Solver к реальной задаче (и напряг мозги, вспоминая школьные основы геометрии).
Выводы
Большое спасибо организаторам! Всё работало как никогда идеально (на той стороне точно не роботы?!).
На мой личный взгляд, по сравнению с некоторыми контестами прошлых лет не хватало нетехнической (хотя бы небольшой художественной) части и/или какого-то discovery. С другой стороны, несмотря на лаконичную спецификацию, сами проблемы были оригинальными, разнообразными, а распределение очков команд на Scoreboard явно свидетельствует об удачном выборе задачи.
На этот раз у нас практически отсутствовало дублирование функциональности: либо размер команды был оптимальным, либо просто не хватало рук, чтобы ещё и велосипедировать, либо мы стали опытнее.
В этом году у нас произошло фиаско с модульными тестами. В первый день новые тесты ещё появлялись, а дальше их как будто только поддерживали. И я тоже. В итоге значительное время каждый день уходило на вылавливание багов всеми участниками.
На протяжении контеста озвучивалось множество идей: и генетические алгоритмы, и метод ветвей и границ, и тот же автоматический аналог PushAction на физической модели -- но даже на проработку откровенно не хватало рук.
В пользу нехватки людей говорит и тот факт, что мы не добрались ни до оптимизации дизлайков, ни до бонусных фич.
Кому интересно, исходники нашего решения лежат здесь.
RetweetFutures. Reactive Streams 2020-11-11
Пояснения и live coding по мотивам этапа 7 Range-запросы проекта курса "Проектирование высоконагруженных систем" в Технополис:
- Устройство
HttpServerизone-nio HttpSession/SessionSelector/SelectorThreadFibonacciIteratorSession.processWrite()/v0/fib?count=<n>
- Кластерные range-запросы
- Read repair
- Expiration
- Server-side processing
- Нагрузочное тестирование через Y!CSB или Yandex.Tank
- Фоновый compaction
- Hinted handoff
- Anti-entropy
- Тесты для consistent/rendezvous hashing
- Блочная компрессия на основе LZ4/Snappy
Futures and Reactive Streams (скачать материалы):
FuturePromise- Трансформеры/комбинаторы
- Callbacks
- Circuit breaker
- Web-сервис на
Future - Проблемы с
Future - Reactive Streams
- Back pressure
- API
Ссылки:
RetweetАсинхронный клиент 2020-10-28
Live coding этапа 6 Асинхронный клиент проекта курса "Проектирование высоконагруженных систем" в Технополис:
- Возможная реализация 5 этапа "Шардирование" a.k.a. baseline
Value.merge()CompletableFuturejava.net.http.HttpClientHttpResponse.BodySubscriber- Асинхронный
GET
Ссылки:
- Actor Model. Futures. Promises
- Реактивный раздатчик ok.ru/music
- Reactive Programming. RxJava (Дмитрий Мельников)
Масштабирование и отказоустойчивость 2020-10-14
Live coding этапа 4 Шардирование проекта курса "Проектирование высоконагруженных систем" в Технополис (скачать материалы):
- Топология
- Способы распределения данных по нодам: modulo/consistent/rendezvous hashing
- HTTP пул соединений к нодам
- Синхронное проксирование запросов
Пояснения к этапу 5 Репликация:
- Replica factor
- Quorum
- Use cases
А также очень кратко пробежались по проблематике:
- Failure detection
- Service discovery
- Балансировка запросов
- Деплой
Релевантные лекции:
- Архитектуры (Саша Христофоров)
- Репликация и шардирование (Дима Щитинин)
- Репликация (Дима Щитинин)
- Современные структуры данных (Дима Щитинин)
- Распределённый консенсус (Дима Щитинин)
- Cassandra (Вадим Цесько)
- Хранение бинарных данных в ОК (Александр Христофоров)
Статьи:
- Эффективные надежные микросервисы (Олег Анастасьев)
- The ϕ Accrual Failure Detector
История Web, highload и модели concurrency в рамках курса Технополис.Highload 2020-10-07
Live coding этапа 3 Асинхронный сервер проекта курса "Проектирование высоконагруженных систем" в Технополис (скачать материалы):
- Вынесение обработки запросов из
SelectorThreadв отдельный пользовательский пул потоков - Нагрузочное тестирование с помощью
wrk2в несколько потоков - Coordinated omission (
wrk2vswrk) - Анализ результатов
А также:
- История Web
- Современные Web сервисы
- Highload и основные определения
- Проблемы многопоточного программирования
- Synchronous vs asynchronous
- Blocking vs non-blocking
- Модели concurrency
- Actor Model
- Примеры систем
- Темы грядущих лекций
Примеры систем на Actor Model:
- Реактивный раздатчик ok.ru/music
- Потоковая фильтрация событий
- Фреймворк Akka и его использование в Яндексе
- Потоковая обработка данных с помощью модели акторов
Релевантные лекции:
- Многопоточность (Рома Иваницкий и Дима Щитинин)
- SRE (Антон Иванов)
- Actor Model. Futures and Promises. Reactive Streams (Вадим Цесько)
Занятие по многопоточности курса Технополис.Highload 2020-09-30
Live coding этапа 2 Многопоточность (ветка stage2) проекта курса "Проектирование высоконагруженных систем" в Технополис:
- Потоко-защищённая реализация
DAOчерезReentrantReadWriteLockи immutableTableSet - Асинхронный flush
MemTableчерез выделенныйThreadиBlockingQueue - Корректное освобождение ресурсов в
DAO.close() - Нагрузочное тестирование с помощью
wrkв несколько потоков - Профилирование с помощью
async-profilerсобытийcpu/alloc/lock - Анализ результатов
Дополнительные материалы:
- Многопоточность (Рома Иваницкий и Дима Щитинин)
- Мониторинг и диагностика JVM (Андрей Паньгин)
- JVM (Андрей Паньгин)
Вводное занятие курса Технополис.Highload 2020-09-23
Вводное занятие курса "Проектирование высоконагруженных систем" в Технополис (скачать материалы):
- Цели и формат курса
- Курсовой проект: распределённый, масштабируемый, отказоустойчивый key-value сервис хранения с HTTP REST API
- Технологический стек: Java 11, one-nio, wrk, async-profiler
- Используем встраиваемый LSM-движок из курсового проекта предыдущего курса NoSQL
- Live coding этапа 1 HTTP + storage
- Содержание будущих лекций
Команда WinterMUTE @ ICFPContest 2020 2020-07-20
У нас были: три демодулятора, пачка интерпретаторов, парсер битовых картинок и целый ворох различных функциональных комбинаторов. Не то, чтобы всё это было нужно для финального зачёта, но если уж собрался участвовать в ICFPC, нужно идти в этом деле до конца.
Антон Волохов
17-20 июля 2020 года прошёл очередной ICFPContest, в котором наша команда WinterMUTE снова приняла участие.
См. наши отчёты о предшествующих ICFPContest 2019 и ICFPContest 2018.
Задача
В этот раз легенда была чумовой: за пару недель до начала соревнований сотрудники Pegovka Observatory начали публиковать необычные сигналы, полученные из космоса, и призвали сообщество помочь их расшифровать. С помощью crowd-sourcing выяснилось, что нам прислали описание простого, но полноценного функционального языка. Наконец, было получено и опубликовано большое сообщение #42 под названием Galaxy.
Одной из первых задач для участников было написание интерпретатора языка для запуска Galaxy. Всё остальное дальше по порядку.
Стоит отметить, что никто из нашей команды внимательно за анонсами, предшествующими контесту, особо не следил, но мы смотрели и обсуждали весёлые ролики, выкладываемые организаторами.
Команда
В этом году из-за злосчастного COVID-19 все взаимодействовали удалённо. Команда была распределённой, но в рамках всего нескольких часовых поясов.
Изначально планировалось участие 8 человек, но перед самым началом соревнований двое выбыли по личным обстоятельствам, один решил организовать свою команду на Python, а ещё один участник присоединился, впрочем, только на нулевой день. В итоге состав был следующим:
- Александр Савин (EPAM)
- Антон Волохов (Apple)
- Алексей Ростовский (JetBrains) -- нулевой и первый день
- Вадим Цесько (Одноклассники)
- Дмитрий Коренев -- нулевой день
- Олег Шпынов (JetBrains Research)
Впрочем, один из наших участников прошлых лет, возможно, оставил нам пасхалку в названии другой команды :)
Решение
Перед соревнованием мы устроили внутреннее голосование и в очередной раз выяснили, что наибольшим общим знаменателем для большинства участников остаётся Java, а на что-то более экзотическое типа Swift, Rust или даже Kotlin в этот раз мы не решились.
Day 0
Организаторы выложили ещё одну пачку полученных и пока не расшифрованных сообщений, составляющих спецификацию языка инопланетян, и предложили совместно разобраться с тем, что они значат, координируясь через общий чатик. Участники постепенно разбирались с новыми сообщениями и предлагали их описание в виде pull request. Как выяснилось, единственными операторами с побочными эффектами были рисование на canvas и взаимодействие со средой, включая отправку координат click.
Оказалось, что у Димы уже есть учебный интерпретатор похожего языка на Haskell и он решил адаптировать его для запуска интерпретации Galaxy. Вадим принимал теоретическое участие и раскуривал спеку. К сожалению, к вечеру Galaxy не заинтерпретировалась из-за недоприменённых функций, но с ходу баг найти не удалось.
Тем временем Олег занялся парсером битовых картинок исходных сообщений пришельцев с прицелом на возможную будущую пользу. Саша взялся запилить правила модуляции/демодуляции данных для взаимодействия с внешней средой. Антон подключился к той же задаче.
К концу первого дня мы научились отправлять первоначальную последовательность от организаторов, но не раскололи, что она значит, и как интепретировать ответ от API.
Day 1
После неудачи с готовым интерпретатором на Haskell Вадим засел за реализацию интерпретатора на Java. Олег успешно распарсил все сырые сообщения, в т.ч. Galaxy, и самостоятельно занялся своим интерпретатором. Антон продолжал заниматься (де)модуляцией, а затем переключился на реализацию поддержки draw. Саша продолжил заниматься (де)модуляцией сложных структур и тестами для них, а затем подключился вместе с Антоном к реализации различных операторов нашего интерпретатора.
Day 2
Интерпретатор Олега успешно прожевал Galaxy. Вадим, Антон и Саша продолжали реализовывать, отлаживать и тестировать интерпретацию операторов языка, а также форсировали ленивость где только можно. Олег тем временем занялся визуализацией оператора draw.
Организаторы, поняв, что у многих команд есть сложности с реализацией интерпретатора, опубликовали псевдокод референсной реализации (на что сетовали в общем чате другие команды, справившиеся с задачей самостоятельно). Олег адаптировал её к нашей модели на Java и мы заверифицировали все наши реализации.
Честно говоря, к этому моменту мы начали ощущать лёгкую депрессию, потому что совершенно не понимали, что от нас ожидается и как другие команды зарабатывают хоть какие-то очки. Из понятного была только спека и задачи по интерпретатору.
Олег ради эксперимента набросал "прокликивалку" по спирали и к концу дня мы увидели Galaxy!
Т.е. прокликивалка "нащупала" последовательность рабочих кликов в UI игры, на очередном цикле интерпретации Galaxy мы заметили, что всё стало "тормозить", а на выходе появились красочные картинки. Мы воодушевились и начали педалить с удвоенной силой.
Антон за половину грядущей ночи разобрался с API, наладил взаимодействие с ним и корректное подключение нашего решения к чемпионатам.
В этот момент стало понятно, что Galaxy сама по себе не нужна, и для участия в чемпионатах достаточно лишь уметь (де)кодировать представление мира и команд.
Саша той же ночью запилил базовую модель игрового мира, с помощью которой можно было программировать поведение нашего бота.
Day 3
Наконец, мы переключились на игровые стратегии, расширение и отладку модели игрового мира, и научились делать что-то нетривиальное. Например, хотя бы пытаться удержаться в рамках игрового пространства с учётом гравитации.
Организаторы продолжали публиковать новые элементы "арсенала", но мы не успели освоить и малую часть. Например, стало возможным клонировать корабли и управлять каждым из них по-отдельности, подлетать и аннигилировать рой противника и т.д.
Итоги
В этот раз по очкам мы были в хвосте, но главная цель получения фана всё-таки была достигнута. Лично я закрыл гештальт написания в сжатые сроки и отладки ленивого интерпретатора функционального языка, способного перемолоть нетривиальную программу Galaxy. А визуальная часть добавила хорошую порцию фана.
Выводы
Организаторам огромный респект за этот большой и красочный опыт раскручивания истории с инопланетянами. Эмоции в тот момент, когда на своих интерпретаторах мы увидели Галактику, описать решительно невозможно.
К сожалению, задание предполагало довольно интенсивный темп до получения хоть какого-то фидбека. В пользу этого говорит хотя бы то, что всего 5 команд в lightning round (к концу первых суток) прошли tutorial #1 -- что это был за tutorial и как в нём поучаствовать, мы так и не поняли.
История с реализацией всех возможностей языка и интерпретацией Galaxy красива сама по себе, но не имела практической ценности для боёв во второй части контеста, на основе которых и строился leader board -- там достаточно было освоить небольшое подмножество языка, чтобы научиться взаимодействовать с игровым API. С другой стороны, Galaxy позволяла отреверсинжинирить всё раньше других команд и продвинуться дальше, что, впрочем, у нас не получилось.
Общий чат всех команд был интересным и, наверное, уникальным решением среди контестов, в которых я участвовал, но у нас практически не хватало времени на его чтение и обсуждение в нём -- не знаю, потеряли ли мы что-нибудь из-за этого.
Как обычно, у нас возникало дублирование функциональности, но тем не менее, все много взаимодействовали и неизбежный фан был получен :)
Очень хорошо показала себя привычка писать и поддерживать модульные тесты -- баги по мере развития решения обнаруживались и исправлялись на ранних стадиях.
В целом, очень хорошо показал себя Google Meet -- мы сидели в нём non-stop все трое суток практически без единого разрыва. Да и сам онлайн формат получился гораздо лучше, чем я лично ожидал.
В текущем контесте возникло ясное осознание, что мы могли бы утилизировать существенно больше человеческих ресурсов (особенно в отдалённых часовых поясах), например, разделившись сразу на разбирательство с API параллельно с проработкой Galaxy.
Подводя итог, хочу поблагодарить участников нашей команды и организаторов контеста -- это было супер!
Исходники нашего решения лежат здесь.
RetweetInterview with Martin Kleppmann before HydraConf 2019 2019-06-27
Thanks to HydraConf got an opportunity to discuss many topics I am interested in with Martin Kleppmann. This interview was originally published by Hydra. It has also been translated into Russian.
Moving from business to academic research
Vadim: The first question I would like to ask you is really important for me. You founded Go Test It and Rapportive, and you had been designing and engineering large-scale systems at LinkedIn for a while. Then you decided to switch from industrial engineering to academia. Could you please explain the motivation for that decision? What have you gained and what have you had to sacrifice?
Martin: It’s been a very interesting process. As you seem to be hinting at, not many people make the switch in that direction. A lot of people go from academia to industry, but not so many back. Which is understandable, because I had to take quite a large pay cut in order to go back to academia. But what I really love about research is the freedom to work on topics that I find interesting and that I think are important, even if those topics don’t immediately lead to a commercially viable product within the next 6 months or so. Of course, at a company the stuff you build needs to turn into a product that can be sold in some form or another.
On the other hand, the things I’m now working on are topics that are really important for the future of how we build software and how the internet works. But we don’t really understand these topics well enough yet to go and start building commercial products: we are still at the level of trying to figure out, fundamentally, what these technologies need to look like. And since this is fundamental research I realized it’s better to do this at a university than to try to do it at a company, because at a university I’m free to work on things that might not become commercially viable for another ten years, and that is OK. It’s OK to work with a much longer time horizon when you’re in research.
Designing Data-Intensive Applications
Vadim: We’ll definitely get back to your current research interests. Meanwhile let’s talk about your latest book Designing Data-Intensive Applications. I’m a big fan of your book and I believe it’s one of the best guides for building modern distributed systems. You’ve covered almost all the notable achievements up to date.
Martin: Thank you, I’m glad you find it useful.
Vadim: Just for those unlucky readers who haven’t read your book yet, could you please name several major achievements in the field of distributed systems nowadays?
Martin: Well, the goal of the book is not so much to explain one particular technology; the goal is rather to give you a guide to the entire landscape of different systems that are used for storing and processing data. There are so many different databases, stream processors, batch processing tools, all sorts of replication tools and so on, and it’s really hard to get an overview. If you’re trying to build a particular application it’s really hard to know which database you should use, and which tools are the most appropriate ones for the problem you’re trying to solve.
A lot of existing computing books simply didn’t answer that problem in a satisfactory way. I found that if you’re reading a book on Cassandra for example, it would tell you why Cassandra is wonderful, but it generally wouldn’t tell you about things for which it’s not a good fit. So what I really wanted to do in this book was to identify the main questions that you need to ask yourself if you’re trying to build some kind of large-scale system. And through answering those questions you can then help figure out which technologies are appropriate and which are less appropriate for the particular problem you’re trying to solve — because, in general, there’s no one technology that is perfect for everything. And so, the book is trying to help you figure out the pros and cons of different technologies in different settings.
Common sense against artificial hype and aggressive marketing
Vadim: Indeed, often — if not always — there are many technologies with overlapping functions, features and data models. And you can’t believe all those marketing buzzwords. You need to read the white papers to learn the internals, and even try to read the source code to understand how it works exactly.
Martin: And I found that you often have to read between the lines because often the documentation doesn’t really tell you for which things a particular database sucks. The truth is that every database sucks at some kind of workload, the question is just to know which ones they are. So yes, sometimes you have to read the deployment guidelines for ops people and try to reverse-engineer from that what is actually going on in the system.
Vadim: Don’t you feel that the industry lacks the common vocabulary or a set of criteria to compare different solutions for the same problem? Similar things are called by different names, some things are omitted which should always be clear and stated explicitly, like transaction guarantees. What do you think?
Martin: Yeah, I think a problem that our industry has is that often, when people talk about a particular tool, there’s a lot of hype about everything. Which is understandable, because the tools are made by various companies, and obviously those companies want to promote their products, and so those companies will send people to conferences to speak about how wonderful their product is, essentially. It will be disguised as a tech talk, but essentially it’s still a sales activity. As an industry, we really could do with more honesty about the advantages and disadvantages of some product. And part of that requires a common terminology, because otherwise you simply can’t compare things on an equal footing. But beyond a shared terminology we need ways of reasoning about things that certain technologies are good or bad at.
Pitfalls of CAP theorem and other industry mistakes
Vadim: My next question is quite a controversial one. Could you please name any major mistakes in the industry you have stumbled upon during your career? Maybe overvalued technologies or widely-practiced solutions we should have got rid of a long time ago? It might be a bad example, but compare JSON over HTTP/1.1 vs the much more efficient gRPC over HTTP/2. Or is there an alternative point of view?
Martin: I think in many cases there are very good reasons for why a technology does one thing and not another. So I’m very hesitant to call things mistakes, because in most cases it’s a question of trade-offs. In your example of JSON over HTTP/1.1 versus Protocol Buffers over HTTP/2, I think there are actually quite reasonable arguments for both sides there. For example, if you want to use Protocol Buffers, you have to define your schema, and a schema can be a wonderful thing because it helps document exactly what communication is going on. But some people find schemas annoying, especially if they’re at early stages of development and they’re changing data formats very frequently. So there you have it, there’s a question of trade-offs; in some situations one is better, in others the other is better.
In terms of actual mistakes that I feel are simply bad, there’s only a fairly small number of things. One opinion that I have is that the CAP Theorem is fundamentally bad and just not useful. Whenever people use the CAP Theorem to justify design decisions, I think often they are either misinterpreting what CAP is actually saying, or stating the obvious in a way. CAP as a theorem has a problem that it is really just stating the obvious. Moreover, it talks about just one very narrowly defined consistency model, namely linearizability, and one very narrowly defined availability model, which is: you want every replica to be fully available for reads and writes, even if it cannot communicate with any other replicas. These are reasonable definitions, but they are very narrow, and many applications simply do not fall into the case of needing precisely that definition of consistency or precisely that definition of availability. And for all the applications that use a different definition of those words, the CAP Theorem doesn’t tell you anything at all. It’s simply an empty statement. So that, I feel, is a mistake.
And while we’re ranting, if you’re asking me to name mistakes, another big mistake that I see in the tech industry is the mining of cryptocurrencies, which I think is such an egregious waste of electricity. I just cannot fathom why people think that is a good idea.
Vadim: Talking about the CAP Theorem, many storage technologies are actually tunable, in terms of things like AP or CP. You can choose the mode they operate in.
Martin: Yes. Moreover, there are many technologies which are neither consistent nor available under the strict definition of the CAP Theorem. They are literally just P! Not CP, not CA, not AP, just P. Nobody says that, because that would look bad, but honestly, this could be a perfectly reasonable design decision to make. There are many systems for which that is actually totally fine. This is actually one of the reasons why I think that CAP is such an unhelpful way of talking about things: because there is a huge part of the design space that it simply does not capture, where there are perfectly reasonable good designs for software that it simply doesn’t allow you to talk about.
Benefits of decentralization
Vadim: Talking about data-intensive applications today, what other major challenges, unsolved problems or hot research topics can you name? As far as I know, you’re a major proponent of decentralized computation and storage.
Martin: Yes. One of the theses behind my research is that at the moment we rely too much on servers and centralization. If you think about how the Internet was originally designed back in the day when it evolved from ARPANET, it was intended as a very resilient network where packets could be sent via several different routes, and they would still get to the destination. And if a nuclear bomb hit a particular American city, the rest of the network would still work because it would just route around the failed parts of the system. This was a Cold War design.
And then we decided to put everything in the cloud, and now basically everything has to go via one of AWS’s datacenters, such as us-east-1 somewhere in Virginia. We’ve taken away this ideal of being able to decentrally use various different parts of the network, and we’ve put in these servers that everything relies on, and now it’s extremely centralized. So I’m interested in decentralization, in the sense of moving some of the power and control over data away from those servers and back to the end users.
One thing I want to add in this context is that a lot of people talking about decentralization are talking about things like cryptocurrencies, because they are also attempting a form of decentralization whereby control is moved away from a central authority like a bank and into a network of cooperating nodes. But that’s not really the sort of decentralization that I’m interested in: I find that these cryptocurrencies are actually still extremely centralized, in the sense that if you want to make a Bitcoin transaction, you have to make it on the Bitcoin network — you have to use the network of Bitcoin, so everything is centralized on that particular network. The way it’s built is decentralized in the sense that it doesn’t have a single controlling node, but the network as a whole is extremely centralized in that any transaction you have to make you have to do through this network. You can’t do it in some other way. I feel that it’s still a form of centralization.
In the case of a cryptocurrency this centralization might be inevitable, because you need to do stuff like avoid double spending, and doing that is difficult without a network that achieves consensus about exactly which transactions have happened and which have not. And this is exactly what the Bitcoin network does. But there are many applications that do not require something like a blockchain, which can actually cope with a much more flexible model of data flowing around the system. And that’s the type of decentralized system that I’m most interested in.
Blockchains, Dat, IPFS, Filecoin, WebRTC
Vadim: Could you please name any promising or undervalued technologies in the field of decentralized systems apart from blockchain? I have been using IPFS for a while.
Martin: For IPFS, I have looked into it a bit though I haven’t actually used it myself. We’ve done some work with the Dat project, which is somewhat similar to IPFS in the sense that it is also a decentralized storage technology. The difference is that IPFS has Filecoin, a cryptocurrency, attached to it as a way of paying for storage resources, whereas Dat does not have any blockchain attached to it — it is purely a way of replicating data across multiple machines in a P2P manner.
For the project that I’ve been working on, Dat has been quite a good fit, because we wanted to build collaboration software in which several different users could each edit some document or database, and any changes to that data would get sent to anyone else who needs to have a copy of this data. We can use Dat to do this replication in a P2P manner, and Dat takes care of all the networking-level stuff, such as NAT traversal and getting through firewalls — it’s quite a tricky problem just to get the packets from one end to the other. And then we built a layer on top of that, using CRDTs, which is a way of allowing several people to edit some document or dataset and to exchange those edits in an efficient way. I think you can probably build this sort of thing on IPFS as well: you can probably ignore the Filecoin aspect and just use the P2P replication aspect, and it will probably do the job just as well.
Vadim: Sure, though using IPFS might lead to lower responsiveness, because WebRTC underlying Dat connects P2P nodes directly, and IPFS works like a distributed hash table thing.
Martin: Well, WebRTC is at a different level of the stack, since it’s intended mostly for connecting two people together who might be having a video call; in fact, the software we’re using for this interview right now may well be using WebRTC. And WebRTC does give you a data channel that you can use for sending arbitrary binary data over it, but building a full replication system on top of that is still quite a bit of work. And that’s something that Dat or IPFS do already.
You mentioned responsiveness — that is certainly one thing to think about. Say you wanted to build the next Google Docs in a decentralized way. With Google Docs, the unit of changes that you make is a single keystroke. Every single letter that you type on your keyboard may get sent in real time to your collaborators, which is great from the point of view of fast real-time collaboration. But it also means that over the course of writing a large document you might have hundreds of thousands of these single-character edits that accumulate, and a lot of these technologies right now are not very good at compressing this kind of editing data. You can keep all of the edits that you’ve ever made to your document, but even if you send just a hundred bytes for every single keystroke that you make and you write a slightly larger document with, say, 100,000 keystrokes, you suddenly now have 10 MB of data for a document that would only be a few tens of kilobytes normally. So we have this huge overhead for the amount of data that needs to be sent around, unless we get more clever at compressing and packaging up changes.
Rather than sending somebody the full list of every character that has ever been typed, we might just send the current state of the document, and after that we send any updates that have happened since. But a lot of these peer-to-peer systems don’t yet have a way of doing those state snapshots in a way that would be efficient enough to use them for something like Google Docs. This is actually an area I’m actively working on, trying to find better algorithms for synchronizing up different users for something like a text document, where we don’t want to keep every single keystroke because that would be too expensive, and we want to make more efficient use of the network bandwidth.
New CRDTs. Formal verification with Isabelle
Vadim: Have you managed to compress that keystroke data substantially? Have you invented new CRDTs or anything similar?
Martin: Yes. So far we only have prototypes for this, it’s not yet fully implemented, and we still need to do some more experiments to measure how efficient it actually is in practice. But we have developed some compression schemes that look very promising. In my prototype I reduced it from about 100 bytes per edit to something like 1.7 bytes of overhead per edit. And that’s a lot more reasonable of course. But as I say, these experiments are still ongoing, and the number might still change slightly. But I think the bottom line is that there’s a lot of room there for optimization still, so we can still make it a lot better.
Vadim: So this is what your talk will be about at the Hydra conference, am I right?
Martin: Yes, exactly. I’ll give a quick introduction to the area of CRDTs, collaborative software and some of the problems that arise in that context. Then I’ll describe some of the research that we’ve been doing in this area. It’s been quite fun because the research we’ve been doing has been across a whole range of different concerns. On the very applied side, we’ve got a JavaScript implementation of these algorithms, and we’re using that to build real pieces of software, trying to use that software ourselves to see how it behaves. On the other end of the spectrum, we’ve been working with formal methods to prove these algorithms correct, because some of these algorithms are quite subtle and we want to be very sure that the systems we’re making are actually correct, i.e. that they always reach a consistent state. There have been a lot of algorithms in the past that have actually failed to do that, which were simply wrong, that is, in certain edge cases, they would remain permanently inconsistent. And so, in order to avoid these problems that algorithms have had in the past, we’ve been using formal methods to prove our algorithms correct.
Vadim: Wow. Do you really use theorem provers, like Coq or Isabelle or anything else?
Martin: Exactly, we’ve been using Isabelle for that.
(You can attend Martin’s talk “Correctness proofs of distributed systems with Isabelle” at The Strange Loop conference in September.)
Vadim: Sounds great! Are those proofs going to be published?
Martin: Yes, our first set of proofs is already public. We published that a year and a half ago: it was a framework for verifying CRDTs, and we verified three particular CRDTs within that framework, the main one of which was RGA (Replicated Growable Array), which is a CRDT for collaborative text editing. While it is not very complicated, it is quite a subtle algorithm, and so it’s a good case where proof is needed, because it’s not obvious just from looking at it that it really is correct. And so the proof gives us the additional certainty that it really is correct. Our previous work there was on verifying a couple of existing CRDTs, and our most recent work in this area is about our own CRDTs for new data models we’ve been developing, and proving our own CRDTs correct as well.
Vadim: How much larger is the proof compared to the description of the algorithm? Because it can be a problem sometimes.
Martin: Yes, that is a problem — the proofs are often a lot of work. I think in our latest example… Actually, let me have a quick look at the code. The description of the algorithm and the data structures is about 60 lines of code. So it’s quite a small algorithm. The proof is over 800 lines. So we’ve got roughly 12:1 ratio between the proof and the code. And that is unfortunately quite typical. The proof is a large amount of additional work. On the other hand, once we have the proof, we have gained very strong certainty in the correctness of the algorithm. Moreover, we have ourselves, as humans, understood the algorithm much better. Often I find that through trying to formalize it, we end up understanding the thing we’re trying to formalize much better than we did before. And that in itself is actually a useful outcome from this work: besides the proof itself we gain a deeper understanding, and that is often very helpful for creating better implementations.
Vadim: Could you please describe the target audience of your talk, how hardcore is it going to be? What is the preliminary knowledge you expect the audience to have?
Martin: I like to make my talks accessible with as little previous knowledge requirement as possible, and I try to lift everybody up to the same level. I cover a lot of material, but I start at a low base. I would expect people to have some general distributed systems experience: how do you send some data over a network using TCP, or maybe a rough idea of how Git works, which is quite a good model for these things. But that’s about all you need, really. Then, understanding the work we’ve been doing on top of that is actually not too difficult. I explain everything by example, using pictures to illustrate everything. Hopefully, everybody will be able to follow along.
Event sourcing and Apache Kafka
Vadim: Sounds really great. Actually, we have some time and I would like to discuss one of your recent articles about online event processing. You’re a great supporter of the idea of event sourcing, is that correct?
Martin: Yes, sure.
Vadim: Nowadays this approach is getting momentum, and in the pursuit of all the advantages of globally ordered log of operations, many engineers try to deploy it everywhere. Could you please describe some cases where event sourcing is not the best option? Just to prevent its misuse and possible disappointment with the approach itself.
Martin: There are two different layers of the stack that we need to talk about first. Event sourcing, as proposed by Greg Young and some others, is intended as a mechanism for data modeling, that is: if you have a database schema and you’re starting to lose control of it because there are so many different tables and they’re all getting modified by different transactions — then event sourcing is a way of bringing better clarity to this data model, because the events can express very directly what is happening at a business level. What is the action that the user took? And then, the consequences of that action might be updating various tables and so on. Effectively, what you’re doing with event sourcing is you’re separating out the action (the event) from its effects, which happen somewhere downstream.
I’ve come to this area from a slightly different angle, which is a lower-level point of view of using systems like Kafka for building highly scalable systems. This view is similar in the sense that if you’re using something like Kafka you are using events, but it doesn’t mean you’re necessarily using event sourcing. And conversely, you don’t need to be using Kafka in order to do event sourcing; you could do event sourcing in a regular database, or you could use a special database that was designed specifically for event sourcing. So these two ideas are similar, but neither requires the other, they just have some overlap.
The case for wanting to use a system like Kafka is mostly the scalability argument: in that case you’ve simply got so much data coming in that you cannot realistically process it on a single-node database, so you have to partition it in some way, and using an event log like Kafka gives you a good way of spreading that work over multiple machines. It provides a good, principled way for scaling systems. It’s especially useful if you want to integrate several different storage systems. So if, for example, you want to update not just your relational database but also, say, a full-text search index like Elasticsearch, or a caching system like Memcached or Redis or something like that, and you want one event to have an updating effect on all of these different systems, then something like Kafka is very useful.
In terms of the question you asked (what are the situations in which I would not use this event sourcing or event log approach) — I think it’s difficult to say precisely, but as a rule of thumb I would say: use whatever is the simplest. That is, whatever is closest to the domain that you’re trying to implement. And so, if the thing you’re trying to implement maps very nicely to a relational database, in which you just insert and update and delete some rows, then just use a relational database and insert and update and delete some rows. There’s nothing wrong with relational databases and using them as they are. They have worked fine for us for quite a long time and they continue to do so. But if you’re finding yourself in a situation where you’re really struggling to use that kind of database, for example because the complexity of the data model is getting out of hand, then it makes sense to switch to something like an event sourcing approach.
And similarly, on the lower level (scalability), if the size of your data is such that you can just put it in PostgreSQL on a single machine — that’s probably fine, just use PostgreSQL on a single machine. But if you’re at the point where there is no way that a single machine can handle your load, you have to scale across a large system, then it starts making sense to look into more distributed systems like Kafka. I think the general principle here is: use whatever is simplest for the particular task you’re trying to solve.
Integrating storage systems: PostgreSQL, Memcached, Redis, Elasticsearch
Vadim: It’s really good advice. As your system evolves you can’t precisely predict the direction of development, all the queries, patterns and data flows.
Martin: Exactly, and for those kinds of situations relational databases are amazing, because they are very flexible, especially if you include the JSON support that they now have. PostgreSQL now has pretty good support for JSON. You can just add a new index if you want to query in a different way. You can just change the schema and keep running with the data in a different structure. And so if the size of the data set is not too big and the complexity is not too great, relational databases work well and provide a great deal of flexibility.
Vadim: Let’s talk a little bit more about event sourcing. You mentioned an interesting example with several consumers consuming events from one queue based on Kafka or something similar. Imagine that new documents get published, and several systems are consuming events: a search system based on Elasticsearch, which makes the documents searchable, a caching system which puts them into key-value cache based on Memcached, and a relational database system which updates some tables accordingly. A document might be a car selling offer or a realty advert. All these consuming systems work simultaneously and concurrently.
Martin: So your question is how do you deal with the fact that if you have these several consumers, some of them might have been updated, but the others have not yet seen an update and are still lagging behind slightly?
Vadim: Yes, exactly. A user comes to your website, enters a search query, gets some search results and clicks a link. But she gets 404 HTTP status code because there is no such entity in the database, which hasn’t been able to consume and persist the document yet.
Martin: Yes, this is a bit of a challenge actually. Ideally, what you want is what we would call “causal consistency” across these different storage systems. If one system contains some data that you depend on, then the other systems that you look at will also contain those dependencies. Unfortunately, putting together that kind of causal consistency across different storage technologies is actually very hard, and this is not really the fault of event sourcing, because no matter what approach or what system you use to send the updates to the various different systems, you can always end up with some kind of concurrency issues.
In your example of writing data to both Memcached and Elasticsearch, even if you try to do the writes to the two systems simultaneously you might have a little bit of network delay, which means that they arrive at slightly different times on those different systems, and get processed with slightly different timing. And so somebody who’s reading across those two systems may see an inconsistent state. Now, there are some research projects that are at least working towards achieving that kind of causal consistency, but it’s still difficult if you just want to use something like Elasticsearch or Memcached or so off the shelf.
A good solution here would be that you get presented, conceptually, with a consistent point-in-time snapshot across both the search index and the cache and the database. If you’re working just within a relational database, you get something called snapshot isolation, and the point of snapshot isolation is that if you’re reading from the database, it looks as though you’ve got your own private copy of the entire database. Anything you look at in the database, any data you query will be the state as of that point in time, according to the snapshot. So even if the data has afterwards been changed by another transaction, you will actually see the older data, because that older data forms part of a consistent snapshot.
And so now, in the case where you’ve got Elasticsearch and Memcached, really what you would ideally want is a consistent snapshot across these two systems. But unfortunately, neither Memcached nor Redis nor Elasticsearch have an efficient mechanism for making those kinds of snapshots that can be coordinated with different storage systems. Each storage system just thinks for itself and typically presents you the latest value of every key, and it doesn’t have this facility for looking back and presenting a slightly older version of the data, because the most recent version of the data is not yet consistent.
I don’t really have a good answer for what the solution would look like. I fear that the solution would require code changes to any of the storage systems that participate in this kind of thing. So it will require changes to Elasticsearch and to Redis and to Memcached and any other systems. And they would have to add some kind of mechanism for point-in-time snapshots that is cheap enough that you can be using it all the time, because you might be wanting the snapshot several times per second — it’s not just a once-a-day snapshot, it’s very fine-grained. And at the moment the underlying systems are not there in terms of being able to do these kinds of snapshots across different storage systems. It’s a really interesting research topic. I’m hoping that somebody will work on it, but I haven’t seen any really convincing answers to that problem yet so far.
Distributed transactions and recovering from bugs
Vadim: Yeah, we need some kind of shared Multiversion Concurrency Control.
Martin: Exactly, like the distributed transaction systems. XA distributed transactions will get you some of the way there, but unfortunately XA, as it stands, is not really very well suited because it only works if you’re using locking-based concurrency control. This means that if you read some data, you have to take a lock on it so that nobody can modify that data while you have that lock. And that kind of locking-based concurrency control has terrible performance, so no system actually uses that in practice nowadays. But if you don’t have that locking then you don’t get the necessary isolation behavior in a system like XA distributed transactions. So maybe what we need is a new protocol for distributed transactions that allows snapshot isolation as the isolation mechanism across different systems. But I don’t think I’ve seen anything that implements that yet.
Vadim: Yes, I hope somebody is working on it.
Martin: Yes, it would be really important. Also in the context of microservices, for example: the way that people promote that you should build microservices is that each microservice has its own storage, its own database, and you don’t have one service directly accessing the database of another service, because that would break the encapsulation of the service. Therefore, each service just manages its own data.
For example, you have a service for managing users, and it has a database for the users, and everyone else who wants to find out something about users has to go through the user service. From the point of view of encapsulation that is nice: you’re hiding details of the database schema from the other services for example.
But from the point of view of consistency across different services — well, you’ve got a huge problem now, because of exactly the thing we were discussing: we might have data in two different services that depends upon each other in some way, and you could easily end up with one service being slightly ahead of or slightly behind the other in terms of timing, and then you could end up with someone who reads across different services, getting inconsistent results. And I don’t think anybody building microservices currently has an answer to that problem.
Vadim: It is somewhat similar to workflows in our society and government, which are inherently asynchronous and there are no guarantees of delivery. You can get your passport number, then you can change it, and you need to prove that you changed it, and that you are the same person.
Martin: Yes, absolutely. As humans we have ways of dealing with this, for example, we might know that oh, sometimes that database is a bit outdated, I’ll just check back tomorrow. And then tomorrow it’s fine. But if it’s software that we’re building, we have to program all that kind of handling into the software. The software can’t think for itself.
Vadim: Definitely, at least not yet. I have another question about the advantages of event sourcing. Event sourcing gives you the ability to stop processing events in case of a bug, and resume consuming events having deployed the fix, so that the system is always consistent. It’s a really strong and useful property, but it might not be acceptable in some cases like banking where you can imagine a system that continues to accept financial transactions, but the balances are stale due to suspended consumers waiting for a bugfix from developers. What might be a workaround in such cases?
Martin: I think it’s a bit unlikely to stop the consumer, deploying the fix and then restart it, because, as you say, the system has got to continue running, you can’t just stop it. I think what is more likely to happen is: if you discover a bug, you let the system continue running, but while it continues running with the buggy code, you produce another version of the code that is fixed, you deploy that fixed version separately and run the two in parallel for a while. In the fixed version of the code you might go back in history and reprocess all of the input events that have happened since the buggy code was deployed, and maybe write the results to a different database. Once you’ve caught up again you’ve got two versions of the database, which are both based on the same event inputs, but one of the two processed events with the buggy code and the other processed the events with the correct code. At that point you can do the switchover, and now everyone who reads the data is going to read the correct version instead of the buggy version, and you can shut down the buggy version. That way you never need to stop the system from running, everything keeps working all the time. And you can take the time to fix the bug, and you can recover from the bug because you can reprocess those input events again.
Vadim: Indeed, it’s a really good option if the storage systems are under your control, and we are not talking about side effects applied to external systems.
Martin: Yes, you’re right, once we send the data to external systems it gets more difficult because you might not be able to easily correct it. But this is again something you find in financial accounting, for example. In a company, you might have quarterly accounts. At the end of the quarter, everything gets frozen, and all of the revenue and profit calculations are based on the numbers for that quarter. But then it can happen that actually, some delayed transaction came in, because somebody forgot to file a receipt in time. The transaction comes in after the calculations for the quarter have been finalized, but it still belongs in that earlier quarter.
What accountants do in this case is that in the next quarter, they produce corrections to the previous quarter’s accounts. And typically those corrections will be a small number, and that’s no problem because it doesn’t change the big picture. But at the same time, everything is still accounted for correctly. At the human level of these accounting systems that has been the case ever since accounting systems were invented, centuries ago. It’s always been the case that some late transactions would come in and change the result for some number that you thought was final, but actually, it wasn’t because the correction could still come in. And so we just build the system with the mechanism to perform such corrections. I think we can learn from accounting systems and apply similar ideas to many other types of data storage systems, and just accept the fact that sometimes they are mostly correct but not 100% correct and the correction might come in later.
Vadim: It’s a different point of view to building systems.
Martin: It is a bit of a new way of thinking, yes. It can be disorienting when you come across it at first. But I don’t think there’s really a way round it, because this impreciseness is inherent in the fact that we do not know the entire state of the world — it is fundamental to the way distributed systems work. We can’t just hide it, we can’t pretend that it doesn’t happen, because that imprecision is necessarily exposed in the way we process the data.
Professional growth and development
Vadim: Do you think that conferences like Hydra are anticipated? Most distributed systems are quite different, and it is hard to imagine that many attendees will get to work and will start applying what they have learned in day-to-day activities.
Martin: It is broad, but I think that a lot of the interesting ideas in distributed systems are conceptual. So the insights are not necessarily like “use this database” or “use this particular technology”. They are more like ways of thinking about systems and about software. And those kinds of ideas can be applied quite widely. My hope is that when attendees go away from this conference, the lessons they take away are not so much what piece of software they should be using or which programming language they should be using — really, I don’t mind about that — but more like how to think about the systems they are building.
Vadim: Why do you think it’s important to give conference talks on such complex topics as your talk, compared to publishing papers, covering all their details and intricacies? Or should anyone do both?
Martin: I think they serve different purposes. When we write papers, the purpose is to have a very definitive, very precise analysis of a particular problem, and to go really deep in that. On the other hand, the purpose of a talk is more to get people interested in a topic and to start a conversation around it. I love going to conferences partly because of the discussions I then have around the talk, where people come to me and say: “oh, we tried something like this, but we ran into this problem and that problem, what do you think about that?” Then I get to think about other people’s problems, and that’s really interesting because I get to learn a lot from that.
So, from my point of view, the selfish reason for going to conferences is really to learn from other people, what their experiences have been, and to help share the experiences that we’ve made in the hope that other people will find them useful as well. But fundamentally, a conference talk is often an introduction to a subject, whereas a paper is a deep analysis of a very narrow question. I think those are different genres and I think we need both of them.
Vadim: And the last question. How do you personally grow as a professional engineer and a researcher? Could you please recommend any conferences, blogs, books, communities for those who wish to develop themselves in the field of distributed systems?
Martin: That’s a good question. Certainly, there are things to listen to and to read. There’s no shortage of conference talks that have been recorded and put online. There are books like my own book for example, which provides a bit of an introduction to the topic, but also lots of references to further reading. So if there are any particular detailed questions that you’re interested in, you can follow those references and find the original papers where these ideas were discussed. They can be a very valuable way of learning about something in greater depth.
A really important part is also trying to implement things and seeing how they work out in practice, and talking to other people and sharing your experiences. Part of the value of a conference is that you get to talk to other people as well, live. But you can have that through other mechanisms as well; for example, there’s a Slack channel that people have set up for people interested in distributed systems. If that’s your thing you can join that. You can, of course, talk to your colleagues in your company and try to learn from them. I don’t think there’s one right way of doing this — there are many different ways through which you can learn and get a deeper experience, and different paths will work for different people.
Vadim: Thank you very much for your advice and interesting discussion! It has been a pleasure talking to you.
Martin: No problem, yeah, it’s been nice talking to you.
Vadim: Let’s meet on July 11 at the conference.
RetweetКоманда WinterMUTE @ ICFPContest 2019 2019-06-24
21-24 июня 2019 года проходил очередной ICFPContest, в котором наша команда WinterMUTE снова принимала участие.
См. наш отчёт об ICFPContest 2018.
Задача
На входе 2D карта лабиринта, по которой перемещается робот с манипуляторами. Цель состоит в посещении всех клеток карты телом робота или манипуляторами за наименьшее время. По карте разбросаны различные booster'ы, позволяющие временно ускоряться, временно обретать способность дрелить препятствия и стены карты или наращивать свои манипуляторы, тем самым увеличивая покрываемую область при движении. Из интересных моментов вспоминается, что при учёте покрытия манипулятором ячейки карты необходимо было учитывать видимость этой ячейки из позиции робота с учётом препятствий, но об этом позже.
В последующих ревизиях спецификации появились бустеры телепортации, а также поддержка клонирования и управления роем роботов и дополнительные наборы карт с новыми бустерами. Итоговый набор всех карт включал 300 карт размером до 400х400 ячеек, как рандомных, так и напоминающих различные страны. Одна из карт была забавным планом USS Enterprise.
Помимо спецификации, наборов карт и примеров решений, организаторы предоставили Web визуализатор и checker карт и решений. Решения от команды отправлялись через API одним архивом с наборами команд для роботов на каждой карте.
Во второй день соревнований организаторами был запущен майнинг lambda coin'ов, которые позволяли покупать бустеры для улучшения времени решения основного набора задач, либо просто увеличивали итоговое число очков команды. Чтобы заработать коины в очередном раунде майнинга необходимо было предоставить решение для текущей задачи раунда и сгенерировать карту, удовлетворяющую заданным в раунде критериям. Впрочем, до этого мы так и не добрались.
В целом, спецификации были лаконичными, понятными и местами забавными.
Команда
Мы собрались более-менее устоявшейся командой в офисе JetBrains:
- Алексей Ростовский (JetBrains)
- Андрей Власовских (JetBrains)
- Вадим Цесько (Одноклассники)
- Дмитрий Щитинин (Одноклассники)
- Олег Шпынов (JetBrains Research)
Решение
Ещё перед началом соревнований мы приняли решение писать на Kotlin. В итоговом репе только Kotlin и JavaScript. Кроме того, мы решили, что в этот раз участвуем ради фана и не пытаемся изо всех сил попасть в ТОП, поэтому будем экспериментировать с альтернативными подходами к решению задачи.
Почему не Rust, как обещали в прошлый раз -- спросите вы? Никто не подготовился и не попытался освоить этот непростой язык, а после изучения спеки стало понятно, что без подготовки ничего дельного мы не напишем. Была ещё одна безумная идея реализовать свой язык поверх Truffle Framework, но после изучения Truffle Tutorial стало понятно, что подготовки понадобится ещё больше, чем к использованию Rust. Впрочем, в контексте задачи текущего контеста ни Rust, ни Truffle нам бы ничего не дали.
Day 1
Contest начался 21 июня в 13:00 по Мск. Все засели за спеку, затем мы совместно проговорили её содержание, чтобы выработать общее понимание, и устроили мозговой штурм, чтобы построить граф задач и наметить даже самые упоротые варианты решения. В отличие от предыдущих соревнований мы пытались воздерживаться от нашего классического подхода к решению похожих задач на основе BFS/A* с эвристиками.
В итоге:
- Лёша с Димой парно занялись моделью карт и роботов
- Олег вызвался расковырять и отреверсинжинирить JavaScript checker от организаторов на основе Scala.js, чтобы переиспользовать его в качестве финального валидатора и скоринг-функции в переборных решениях
- Андрей с Вадимом взялись парно за решатель на основе генетических алгоритмов
К концу дня была готова первая версия развесистой, но чёткой модели предметной области с геометрией, пространством и перемещениями робота, а также сериализацией (и с true-типами для координат X и Y), завели JsVM на основе Nashorn (который Андрей сконвертил с Java в Kotlin) и запустили пример тестового генетического решателя на основе Jenetics. Для ускорения интерпретации JavaScript перешли с Java 11 и Nashorn на GraalVM.
Не обижайтесь на матерные имена функций и комментарии на немецком в JsVM -- полёт мысли при деобфускации было трудно остановить. Кроме того, коммиты Олега в JavaScript часть плохо открываются на Bitbucket в силу своего размера.
Day 2
Андрей с Олегом заинтегрировали JsVM в качестве scoring-функции в генетический решатель карт, подбирающий минимальную последовательность команд для покрытия всей карты, и занялись улучшением scoring'а, чтобы соптимизировать перебор и сделать его более направленным, а также обеспечить управляемый останов при недостижении решения за ограниченное число итераций. Генетический решатель смог решить первую тривиальную карту (решение было отправлено в lightning round), но все остальные (топологически гораздо более сложные) карты представляли вычислительную проблему. Кроме того, профилирование async-profiler'ом показало, что JsVM исполняется в интерпретаторе и непрерывно перекомпилируется и непонятно было, что с этим делать. Кеширование JavaScript Contextов, чтобы переиспользовать разные инстансы JsVM при генетическом скоринге, не дало эффекта.
Лёша с Димой продолжили работу над развитием модели и интерпретатором решений, попутно реализовав дампилку карт в псевдографике и поддержав телепортацию и клонирование, а также сериализацию форматов и реализацию видимости манипуляторов (с рациональными числами), и начали имплементировать алгоритм обхода карты на основе DFS. К слову, только в этом компоненте были замечены тесты.
Олег продолжил деобфусцировать и оптимизировать Scala.js код checker'а, а также начал работу над альтернативным ручным визуальным и автоматическим жадным решателем карт.
Андрей уехал на конференцию, Вадим занялся инфраструктурой запуска решателей на всех картах и выбором лучших решений для отправки, а после этого попытался формализовать задачу и свести её к SMT, чтобы применить Z3.
Day 3
DFS-решатель от Лёши и Димы начал успешно обходить карты и, наконец, мы начали отправлять решения. Ручной решатель от Олега завёлся и позволил отлаживать решения, а также строить оптимальные ручные решения для небольших карт.
После просмотра визуализации DFS-решений (сопровождающегося комментариями "ты чё, пёс, куда пошёл?!") стало понятно, что алгоритм на основе простой BFS-эвристики может работать лучше -- на каждом шаге будем идти к ближайшей непосещённой ячейке. Дима и Вадим на коленке запедалили BFS-алгоритм и смогли улучшить результат DFS.
Лёша с Димой внедрили эвристику по приоритетному собиранию booster'ов для расширения манипуляторов, поскольку они позволяют увеличить покрытие ячеек при путешествии робота по карте, что дало профит на большинстве карт.
Попутно всплыли проблемы с некорректной оценкой видимости ячеек под манипуляторами, которые Дима с Олегом героически пофиксили, что позволило отправить решения ко всем задачам.
Олег продолжил улучшать ручной и жадный решатели, но мы успели добиться улучшения лишь по некоторым картам.
У Вадима с Z3 ничего полезного не вышло, поскольку солвер зацикливался из-за использования квантификаторов, и лишь после завершения контеста возникла идея, как можно было сузить область поиска.
Итоги
В итоговой таблице мы на 73 месте из 142 команд с ненулевыми очками.
Надеюсь, в этом посте я более-менее объективно описал вклад каждого участника и ничего не забыл. Дальше изложен ряд моих собственных мыслей на тему прошедшего контеста.
Kotlin
На этот раз Kotlin показал себя норм, IDEA не крешилась через раз, хотя код пестрел операциями !!.
Решение
Наконец-то, мы попробовали альтернативные подходы к решению задачи. К сожалению, это ничем не помогло, но добавило драйва.
Команда
Мы рассчитывали на 6 человек, но в итоге full-time участовали только четверо. Наверное, можно было достигнуть большего за счёт распараллеливания.
На мой взгляд, парное программирование снова хорошо показало себя.
Выводы
Как и всегда, было офигенно. Снова возникло это почти забывшееся за год ощущение, сколько можно сделать всего за 3 дня.
Спасибо Илье Сергею за организацию ICFPContest! Кстати, все исходники инфраструктуры контеста выложены в общий доступ.
Если есть, что сказать, добро пожаловать в комменты!
RetweetРеактивный раздатчик ok.ru/music 2018-10-19
Выступил с докладом "Реактивный раздатчик ok.ru/music" на Joker 2018.
Раздатчик музыки непосредственно занимается отдачей байтов аудиопотока многочисленным пользователям https://ok.ru/music. В пике суммарный трафик достигает 100 Гб/с через сотни тысяч соединений, а время до первого байта составляет не больше 100 мс. Предыдущая версия раздатчика на основе файлов и Apache Tomcat не устраивала нас требуемым количеством оборудования и неспособностью утилизировать современное железо. При разработке новой версии мы поставили перед собой цель сохранить внешнюю функциональность сервиса неизменной, но обойтись существенно меньшим количеством машин, сохранив при этом масштабируемость и отказоустойчивость сервиса.
В докладе мы рассмотрим, как различные архитектурные решения помогли нам обеспечить масштабируемость и отказоустойчивость сервиса за счёт распределения и репликации музыкальных треков между нодами. Затем подробно поговорим про устройство отдельной ноды, включая отказоустойчивую подсистему хранения, сетевую подсистему, а также использование подхода reactive streams. Уделим особое внимание собранным граблям и трюкам, позволившим увеличить производительность системы, упростить отладку и эксплуатацию системы.
Доклад ориентирован на разработчиков, которые хотят расширить свой арсенал подходов и инструментов для создания распределённых и/или высоконагруженных систем с интенсивным I/O.
RetweetКоманда WinterMUTE @ ICFPContest 2018 2018-07-24
20-23 июля 2018 года проходил очередной ICFPContest, где наша команда WinterMUTE снова принимала участие.
Disclaimer
Окончательные результаты соревнований ещё не опубликованы, но мы отчётливо понимаем, что не заняли никаких топовых мест. Тем не менее, это было интересно, и я просто хочу описать по свежим следам, как это было, чтобы сподвигнуть кого-нибудь ещё поучаствовать в таком крутейшем ежегодном мероприятии.
Задача
Итак, на входе алгоритма дискретная 3D модель (матрица) размером до 250х250х250 вокселей (см. анимацию), представленная в виде вектора битов. Необходимо предоставить трассу из набора команд для управления наноботами, которые построят указанную модель.
Наноботы могут:
- Перемещаться различными ограниченными способами
- Расщепляться и сливаться
- Создавать и дезинтегрировать воксели
- Ждать
Симуляция системы осуществляется в дискретном времени. Всё начинается и заканчивается единственным наноботом, который стоит в начале координат. На каждом такте симуляции каждый нанобот выполняет ровно одну команду.
В lightning round (заканчивается через одни сутки с момента старта соревнований) Nanobot Matter Manipulation System поддерживала до 20 наноботов и требовалось строить модели, начиная с пустого пространства.
В full round Deluxe Nanobot Matter Manipulation System позволяла использовать до 40 наноботов и поддерживала операции групповой заливки/уничтожения вокселей. При этом появились два новых типа заданий:
- Разобрать входную модель
- Перестроить модель на входе в заданную модель на выходе
В системе задана нетривиальная целевая функция расчёта потраченной энергии, которая зависит от выполняемых наноботами команд (создание/расщепление материи, перемещение и др.) и количества наноботов, а также количества шагов симуляции в двух режимах "резонансного поля":
- Low, когда модель должна быть grounded по аналогии с "реальными", т.е. от каждого вокселя должен существовать путь через непосредственных соседей к подставке-основанию
- High, когда воксели могут "левитировать" в пространстве
High режим гораздо дороже с точки зрения энергии и между режимами можно переключаться (если выполняется условие groundedness).
Разумеется, на каждом такте работы системы проверяется отсутствие коллизий при перемещении наноботов (между собой и со стенами).
Участникам для каждой проблемы предоставляется пример решения, где один нанобот "змейкой" строит модель, находясь всё время в режиме High.
Модели и трассы (команды) упакованы в компактные битовые представления. Организаторы выдали client-side визуализацию моделей и симулятор трасс на WebGL.
Цель
Для каждой проблемы (сборка/разборка/пересборка модели) предложить наилучшее решение (трассу из набора команд для наноботов) с точки зрения потраченной энергии.
Команда
Мы собрались более-менее устоявшейся командой в офисе Одноклассников:
- Александр Савин (Яндекс.Вертикали) -- lightning round
- Алексей Захаров (Яндекс.Вертикали) -- lightning round
- Антон Волохов (Apple)
- Вадим Цесько (Одноклассники)
- Дмитрий Щитинин (Яндекс.Вертикали)
- Олег Шпынов (JetBrains Research)
Решение
Ещё перед началом соревнований мы спонтанно приняли решение писать на связке Java и Python. В итоговом репе только Java и JavaScript.
Day 0
Contest начался 20 июля в 19:00 по Мск, поэтому мы посвятили несколько часов разбору задания, генерации идей по его решению и рассмотрению извращённых примеров 2D моделей на доске, а затем разошлись по домам думать.
Day 1
Собрались пораньше и начали писать код. Олег заинтересовался JS кодом симулятора/визуализатора от организаторов и занялся его изучением и деобфускацией (чем и продолжил заниматься оставшиеся дни). Остальные члены команды разбились по парам и отправились кодить обязательные части: наше внутреннее представление состояния системы наноботов в матрице, координаты, десериализаторы входных моделей и сериализаторы выходных трасс. При этом всё обильно покрывали тестами.
Решили пойти по пути создания детерминированных стратегий решения задач и реализовать следующую архитектуру (сверху вниз):
- Стратегии (управление роем наноботов, разборка/сборка моделей по слоям, декомпозиция моделей и т.д.)
- API (геометрические примитивы и алгоритмы, высокоуровневые команды перемещения и т.д.)
- VM (интерпретация команд в терминах официальной спеки, поддержание состояния матрицы, накопление трассы, проверка ограничений и инвариантов, оценка потраченной энергии и т.д.)
К концу дня Саша, Дима и Вадим дописали основную обвязку и реализовали SwitchVM. Тем временем Олег сократил код JS с 30К до 14К строк. Антон с Алексеем занимался кодом "парковки" в начале координат после построения модели, а затем начал пилить простейшую стратегию, которая собирает модель одним наноботом, но более эффективно, чем дефолтные трассы от организаторов.
Тем временем, lightning round закончился, мы ничего не отправили. Организаторы опубликовали условия Full Round, где были добавлены групповые команды заливки и уничтожения вокселей (к слову, Олег обнаружил их в коде JS загодя), увеличено максимальное количество наноботов, а также опубликованы новые проблемы сборки, разборки и пересборки моделей.
Day 2
Собрались пораньше, посокрушались, что не успели ничего доделать до окончания lightning round, и продолжили кодить. Нас осталось четверо.
Первым делом Дима поддержал групповые GFill/GVoid и переключился на создание стратегии послойной разборки моделей сверху-вниз. Вадим занялся автоматизацией прогона и отправки решений, а затем начал разрабатывать утильные примитивы горизонтальных плоскостей и проверки groundness с помощью BFS. Олег продолжил разбирать JS организаторов на части, чтобы переиспользовать в качестве валидатора и оценщика энергии. Антон существенно развил стратегию сборки моделей MothershipStrategy, использующую рой наноботов, и доотлаживал её. MothershipStrategy распределяла строки каждой горизонтальной плоскости между ботами, которые строили свою часть снизу вверх.
Мы начали сабмитить наши решения для набора задач по сборке моделей, используя MothershipStrategy, хотя и не поднимались выше 37 места в таблице. Нужно было научиться решать оставшиеся задачи (благодаря будущей DisassemblyStrategy), а также улучшать существующие стратегии.
Тем не менее, к концу дня драйв нарастал, поскольку всё это уже работало.
Day 3
Олег запустил перепиленый JS-симулятор организаторов под Nashorn, научился подавать ему входные данные извне, а также перехватывать callbackи ошибок и успеха, и начал интегрировать его в наш CI. Дима продолжил возводить DisassemblyStrategy, а Антон -- улучшать MothershipStrategy. Вадим вылавливал баги, добавил поддержку решения оставшихся проблем, запилил простейшую статистику и занялся изучением моделей из новых проблем.
Ближе к дедлайну заработала DisassemblyStrategy, которая работала как утюг на основе GVoid, что дало возможность решать задачи разборки и пересборки моделей. Впрочем некоторые задачи решить не удалось из-за оставшихся багов, но мы засабмитили то, что успели решить.
Итоги
Надеюсь, в этом посте я более-менее объективно описал вклад каждого участника и ничего не забыл. Дальше изложен ряд моих собственных мыслей на тему прошедшего контеста.
Java
IMHO, Java не подходит для решения подобных задач в сжатые сроки -- слишком много boilerplate кода и невыразительная система типов. Не хватало функций высших порядков, data/case classes, pattern matching и т.д. (чего стоят постоянные преобразования (short) 1 и отладка перепутанных координат). Впрочем, код на Java предельно "тупой", что позволяло быстро разбираться в чужом коде. При этом написание нетривиальных стратегий вызывало боль и страдание.
В следующий раз мы предварительно договорились попробовать язык Rust.
Scoring
С одной стороны, фиксированный набор готовых вариантов проблем от организаторов упрощал разработку и CI. Client-side визуализаторы и симуляторы устраняли необходимость дёргать какой-либо API. С другой стороны, это теоретически позволяло отправить для каждой проблемы какое-то кастомное решение. Возможно, было бы "честнее", если бы окончательная оценка решений осуществлялась запуском бинарников участников на отдельном оценивающем наборе задач (как когда-то в ICFPC про Pacman).
Решение
В этом раз (как и в предыдущие) мы применили классический инженерный подход к решению задачи. Было бы интересно взглянуть на проблему с принципиально иной точки зрения, например, попытаться свести задачу к известной, попробовать SAT-солверы, генетические/рандомизированные подходы или что-нибудь ещё.
Команда
На мой взгляд, было хорошей идеей программировать парно. Кроме того, неплохое покрытие тестами позволяло бесстрашно наносить улучшения чужому коду. Тем не менее, на второй день все почувствовали, что при большем количестве участников мы смогли бы сделать больше. Мы не успели полностью реализовать проверку возможных коллизий и расчёт энергии для текущей трассы, использовать GFill в MothershipStrategy. Впрочем, стратегии по построению избегали коллизий.
В целом, это было чертовски круто! Трудно объяснить, почему круто. Это можно только почувствовать на собственном примере. Лично у меня после каждого ICFPC возникает ощущение, что нет ничего невозможного и за 3 дня можно подобраться к какому-никакому решению любой задачи.
Огромное спасибо организаторам за проделанную работу! Мне трудно представить, сколько усилий было потрачено на разработку, отладку и тестирование всей этой машинерии.
В корне проекта лежит README для организаторов.
Если есть, что сказать, добро пожаловать в комменты!
RetweetActor Model, Futures and Promises, Reactive Streams 2018-05-23
В рамках магистерского курса "Параллельные вычисления" на кафедре КСПТ прочитал лекцию "Actor Model" (скачать слайды):
- Actor Model
- Use Cases
- Futures and Promises
- Reactive Streams
NoSQL 03. Cassandra. Haystack. 2018-05-16
Третья лекция раздела NoSQL курса "Базы данных" в Технополисе.
- Модель данных
- Архитектура
- Детали реализации
- Background
- Архитектура
- Детали реализации
NoSQL 02. CAP. Raft. 2018-04-25
Вторая лекция раздела NoSQL курса "Базы данных" в Технополисе (скачать слайды, видео 1, видео 2):
- CAP теорема
- Распределённые транзакции
- Отношение happens-before
- Протокол Raft
Индивидуальный курсовой проект лежит на GitHub.
RetweetТехнополис.NoSQL 01. Введение. Hash and Cache. 2018-04-04
Первая лекция раздела NoSQL курса "Базы данных" в Технополисе (скачать слайды):
- Определения и примеры
- Классификация СУДБ
- Web Scale
- Hashing
- Caching
- Key-value хранилища
Индивидуальный курсовой проект лежит на GitHub.
RetweetТехнополис. Курс HighLoad. 2018-02-01
В рамках курса "Проектирование высоконагруженных систем" для студентов 3-го семестра образовательного проекта Технополис прочитал лекцию "Введение" (скачать слайды):
- История Web
- Цель курса
- Будущие лекции
- Источники
- Курсовой проект (варианты решений среди закрытых pull request'ов)
Видео и слайды всех лекций курса собраны в блоге Одноклассников на Хабрахабр.
Мы ищем разработчиков и стажёров в команду.
RetweetActor Model, Futures and Promises, Reactive Streams 2017-05-25
В рамках магистерского курса "Параллельные вычисления" на кафедре КСПТ прочитал лекцию "Actor Model" (скачать слайды):
- Actor Model
- Use Cases
- Futures and Promises
- Reactive Streams
NoSQL 03. Cassandra. Haystack. 2017-05-24
Третья лекция раздела NoSQL курса "Базы данных" в Технополисе.
- Модель данных
- Архитектура
- Детали реализации
NoSQL 02. CAP. Raft. 2017-05-10
Вторая лекция раздела NoSQL курса "Базы данных" в Технополисе (скачать слайды):
- CAP теорема
- Распределённые транзакции
- Отношение happens-before
- Протокол Raft
NoSQL 01. Введение. Hash and Cache. 2017-04-26
Первая лекция раздела NoSQL курса "Базы данных" в Технополисе (скачать слайды):
- Определения и примеры
- Классификация СУДБ
- Что значит Web Scale
- Hashing
- Caching
- Key-value хранилища
The Art of JVM Profiling 2017-04-07
The Art of JVM Profiling talk by Andrei Pangin and me has been accepted by JPoint 2017 conference (slides).
No Java profiler is perfectly accurate, since JDK does not provide sufficient means to find where CPU time is exactly spent. Even "honest" profilers based on private HotSpot APIs will not tell the whole truth. Hardware counters and kernel functions could probably help, but unfortunately they are not aware of Java code at all. We will discuss several approaches to Java profiling: JVM TI, AsyncGetCallTrace, perf_events and Flame Graphs. Their principles and limitations will be considered. We will find a way to combine the advantages of all approaches together. Finally, we will see how Odnoklassniki performs full-stack profiling in production: from Java code down to Linux kernel.
RetweetStreaming Matching of Events 2017-02-05
Dmitry Schitinin gave talk about Streaming matching of events at CEE-SEC(R) 2016 conference.
Our paper is published by ACM in the proceedings of the conference (backup PDF).
In Russian:
RetweetYoctoDB @ Yandex.Classifieds 2016-08-31
YoctoDB @ Yandex.Classifieds talk has been accepted by CEE-SEC(R) 2016 conference (slides).
The paper is published by ACM in the proceedings of the conference (backup PDF).
We are going to present recently open sourced YoctoDB project — a small embedded Java-engine for extremely fast partitioned immutable-after-construction databases. We will briefly describe the architecture of indexing and search components, role and requirements on the search engine and our previous solution. Then we will dive into design and implementation of YoctoDB engine currently being used at Yandex.Auto and Auto.ru. In conclusion we will describe several Java pitfalls met along the way, the limitations of the approach and directions of future development.
The talk is targeted at software engineers and architects building high-load search systems and willing to optimize resource consumption and service latency. Design decisions and trade-offs are described to help implementing similar robust data processing pipelines.
In English:
In Russian:
RetweetActor Model, Futures and Promises, Reactive Streams 2016-05-11
В рамках магистерского курса "Параллельные вычисления" на кафедре КСПТ прочитал лекцию "Actor Model" (скачать слайды):
- Actor Model
- Use Cases
- Futures and Promises
- Reactive Streams
В отличие от лекции прошлого года расширены примеры систем на Actor Model и добавлен раздел про Reactive Streams.
RetweetUnique Action Counting 2015-08-30
I will describe our approach to unique user action counting using Cassandra. An action is a click, a page view, a phone call or anything similar. Each action connects an object and a user.
A counter for a specific action provides the following methods:
- Connect the user and the object
- Count unique users connected to the object
Sets of users and objects are effectively infinite, but they increase gradually -- new ones appear and former ones don't appear any more. We don't want to run out of space because of storing connections forever, so we need some expiration policy. More about it later.
Data model
Cassandra schema looks like this:
CREATE TABLE IF NOT EXISTS $TABLE(
id varchar,
t varchar,
PRIMARY KEY (id, t))
WITH
compaction = {
'class': 'LeveledCompactionStrategy'
} AND
default_time_to_live = $TTLid is an object id. t is a token identifying user.
As it follows from the schema:
- Token is a clustering key, so only unique tokens are stored
- Tokens are partitioned by objects, so we can issue effective object's unique token counting requests
- LeveledCompactionStrategy tries to store per object rows in a few SSTables to speed up read requests
- We use Cassandra TTL feature to forget about disappeared objects and users
Requests
We have only two kinds of requests.
A request connecting the object and the token:
INSERT INTO $TABLE(id, t) VALUES (:id, :t)A request counting unique tokens associated with the object:
SELECT COUNT(1) as counter FROM $TABLE WHERE id = :id LIMIT $LIMITWe use explicit counter limit to bound the response time in case of extremely (or artificially) popular object.
Both requests are executed with LOCAL_ONE consistency level.
DAO
The DAO uses requests considered before and is based on the official Cassandra Java driver.
Cassandra driver is configured the following way:
Cluster.builder()
.addContactPoints(clusterNodes: _*)
.withCompression(ProtocolOptions.Compression.LZ4)
.withLoadBalancingPolicy(
new TokenAwarePolicy(
new DCAwareRoundRobinPolicy(
localDataCenter,
remoteNodes)))
The implementation uses Session.executeAsync() and is fully asynchronous.
HTTP API
HTTP API is quite simple and delegates to the DAO. Let's HTTP requests.
Get count of tokens connected with object object_id:
$ curl http://myhost/api/v1/counter/object_id
42Connect token token to object object_id and return count of tokens:
$ curl -X PUT -d token http://myhost/api/v1/counter/object_id
43When implementing HTTP API we used Spray.
Benchmarks
We have a two node Cassandra cluster. Each node is a 16 core (with HT) 64 GB SSD machine.
Cassandra keyspace configuration is the following:
replication = {'class': 'NetworkTopologyStrategy', 'DC1': '2'} AND durable_writes = trueHTTP API runs on a 32 core machine.
Test load
The test load depends on two parameters:
- Total number of requests
- Total number of objects
Each test request can be expressed like this:
$ curl -X PUT -d token http://myhost/api/v1/counter/object_idWhere token is a random long value and object_id
is an int value between 0 and total number of objects
chosen using Gaussian distribution to model hot (popular) objects.
100 objects and 10M tokens
Cassandra nodes' CPUs get fully saturated at 700 rps load. The stable load area:
Some numbers:
- 50% of requests < 5 ms
- 99.8% of requests < 50 ms
- 99.95% of requests < 100 ms
1K objects and 10M tokens
Cassandra nodes' CPUs get fully saturated at 2.5 Krps load. The stable load area:
Some numbers:
- 50% of requests < 2 ms
- 99.5% of requests < 50 ms
- 99.68% of requests < 100 ms
- 99.84% of requests < 300 ms
- 99.94% of requests < 500 ms
Conclusion
We considered unique action counters on top of Cassandra storage. This implementation (with some minor changes and caching added) is used in all the user facing counters in Yandex.Auto, Yandex.Realty and Yandex.Rabota.
Next time we might consider:
- Probabilistic persistent caching using Cassandra static columns
- Non unique counters (clickers) and rate limiters based on Cassandra
Croudfunding на подарок 2015-03-16
Если решили, но не придумали, что мне подарить, то знайте, что я коплю на наушники с активным шумоподавлением для ментальной изоляции в условиях openspace-офиса:
RetweetActor Model 2014-11-21
В рамках магистерского курса "Параллельные вычисления" на кафедре КСПТ прочитал лекцию "Actor Model" (скачать слайды):
- Actor Model
- Futures and Promises
- Примеры систем
Темы "Dataflow Concurrency" и "Software Transactional Memory" не рассматривались, поскольку поддержка в Akka приостановлена. См. лекции прошлого года.
RetweetДокументация и бенчмарки YoctoDB 2014-08-24
Наконец, дошли руки и смог написать более подробную документацию по YoctoDB:
- Мотивация или нафига мы это делали
- Внутреннее устройство, а точнее основные понятия и связи
- Внутренние бенчмарки на реальной нагрузке Яндекс.Авто
- Как начать использовать или show me the code
YoctoDB 2014-07-04
Выложили в OpenSource встраиваемую СУБД YoctoDB, разработанную в Яндекс.
Ждите подробных постов про мотивацию и внутреннее устройство.
RetweetФреймворк Akka и его использование в Яндексе 2014-04-18
Выступил на JPoint 2014 с докладом "Фреймворк Akka и его использование в Яндексе" (скачать слайды).
Модель акторов известна уже 20 лет, но при этом её элегантность и выразительность продолжают доставлять. Наиболее известной реализацией является среда выполнения Erlang, использующаяся во многих промышленных системах. В то же время набирает популярность реализация модели акторов во фреймворке Akka, базирующемся на опыте Erlang, нацеленном на JVM и имеющем API для Scala и Java.
Мы подробно рассмотрим модель акторов на примере Akka/Scala и наш опыт её применения в сервисах, уже запущенных или ещё разрабатываемых в Яндексе. Будем говорить о задачах, архитектурах, принятых (и отвергнутых) решениях, достоинствах и недостатках, а также разложенных местами граблях и обходных путях для них.
RetweetPrinciples of Reactive Programming 2014-01-21
Получил 100% в курсе Principles of Reactive Programming на Coursera. Рекомендую.
RetweetБазы данных. Задание FR11 2013-12-09
-
Фильтрация и возврат значений по диапазону ключей на стороне сервера (server-side filter)
-
Преобразование значений по диапазону ключей на стороне сервера (update in-place)
-
Тесты
FR11 сгорает 2013-12-09.
RetweetБазы данных. STM 2013-12-09
Лекция "Software Transactional Memory" (скачать слайды):
Посмотреть видео на сайте Лекториума.
См. множество ссылок в презентации.
RetweetБазы данных. Multidimensional indexing 2013-12-02
Гостевая лекция "Multidimensional indexing" (скачать слайды) Антона Волохова в курсе "Базы данных" в Computer Science Center.
Посмотреть видео на сайте Лекториума.
RetweetБазы данных. Задание FR10 2013-12-02
-
Многопоточная нода (размеры пулов настраиваются)
-
Тесты производительности (масштабируемость по ядрам)
-
Поддержка атомарных batch-запросов
-
Тесты корректности
FR10 сгорает 2013-12-02.
RetweetActor Model 2013-11-29
В рамках магистерского курса "Параллельные вычисления" на кафедре КСПТ прочитал лекцию "Actor Model" (скачать слайды):
- Actor Model
- Futures and Promises
- Dataflow Concurrency
- Software Transactional Memory
Базы данных. Задание FR9 2013-11-25
-
Хранение значений блоками в сжатом виде (Snappy, LZ, etc.)
-
Сжатие отключаемо
-
Тесты (в т.ч. эффективности)
FR9 сгорает 2013-11-25.
RetweetБазы данных. Graph DB 2013-11-25
Гостевая лекция "Graph DB" (смотреть слайды) Ильи Тетерина в курсе "Базы данных" в Computer Science Center.
Посмотреть видео на сайте Лекториума.
RetweetБазы данных. Lucene 2013-11-18
Гостевая лекция "Lucene" (скачать слайды) Германа Андреева в курсе "Базы данных" в Computer Science Center:
Посмотреть видео на сайте Лекториума.
RetweetБазы данных. Задание FR8 2013-11-18
-
Аналогично Redis Hashes (счётчики необязательны)
-
Тесты
FR8 сгорает 2013-11-18.
RetweetБазы данных. ZooKeeper 2013-11-11
Гостевая лекция "ZooKeeper" (скачать слайды) Дмитрия Щитинина в курсе "Базы данных" в Computer Science Center:
Посмотреть видео на сайте Лекториума.
RetweetБазы данных. Задание FR7 2013-11-11
-
Развитие FR4
-
Репликация по кольцу
-
Клиент задаёт количество нод при записи/чтении
-
Логи
-
Тесты
FR7 сгорает 2013-11-11.
RetweetБазы данных. Задание FR6 2013-11-04
-
Развитие FR4
-
Автоматическая балансировка данных при добавлении узла
-
Ручная балансировка при удалении узла
-
Возможность смотреть и редактировать кольцо
-
Логи
-
Тесты
FR6 сгорает 2013-11-04.
Зачтено
RetweetБазы данных. Задание FR5 2013-10-28
-
Развитие FR1
-
Размер на диске не больше 2х объёма актуальных (живых) ключей
-
Автоматический фоновый запуск
-
Возможность ручного запуска
-
Логи
-
Тесты
FR5 сгорает 2013-10-28.
Зачтено
-
Суворов Егор -- +1 бонусный балл
Базы данных. Задание FR4 2013-10-28
Минимальная функциональность:
-
Динамическая конфигурация (добавляем и удаляем узлы на лету)
-
Например, 2PC новой конфигурации
-
Graceful Degradation
-
Consistent Hashing
-
Миграция партиций при добавлении/удалении узлов
-
Тесты
FR4 сгорает 2013-10-28.
RetweetБазы данных. HBase 2013-10-28
Гостевая лекция "HBase" (скачать слайды) Леонида Налчаджи в курсе "Базы данных" в Computer Science Center:
Посмотреть видео на сайте Лекториума.
RetweetБазы данных. HDFS 2013-10-21
Гостевая лекция "HDFS" (скачать слайды) Леонида Налчаджи в курсе "Базы данных" в Computer Science Center:
Посмотреть видео на сайте Лекториума.
RetweetБазы данных. Задание FR3 2013-10-21
Минимальная функциональность:
-
Commit-log от master к slaves
-
Статическая конфигурация
-
Клиент знает конфигурацию: пишет в master, читает из slaves
-
Модульные тесты
FR3 сгорает 2013-10-21.
Зачтено
RetweetБазы данных. Задание FR1 2013-10-14
Минимальная функциональность:
-
Key-Value API
-
Данные не влезают в память (>= 4 ГБ)
-
Используйте открытые источники данных (из лекций)
-
Стресстест в виде shell-скрипта или модульного теста (
-Xmx1g)
FR1 обязателен и не приносит баллов всем, кроме выполнивших в срок FR0.
Зачтено
-
Ершов Василий -- +1 бонусный балл
-
Суворов Егор -- +1 бонусный балл
Базы данных. Haystack 2013-10-14
Лекция "Haystack" (скачать слайды) про хранение фоток в Facebook по статье "Finding a Needle in Haystack: Facebook's Photo Storage" (скачать статью):
Посмотреть видео на сайте Лекториума.
RetweetБазы данных. Задание FR2 2013-10-14
Минимальная функциональность:
-
Равноправные узлы
-
Данные распределены по кластеру
-
Статическая конфигурация (узлы и диапазоны ключей)
-
Клиент знает конфигурацию
-
Модульные тесты
FR2 сгорает 2013-10-14.
Зачтено
RetweetБазы данных. MongoDB 2013-10-07
Гостевая лекция "MongoDB is a web-scale" (скачать слайды) Антона Волохова в курсе "Базы данных" в Computer Science Center:
Посмотреть видео на сайте Лекториума.
См. множество ссылок в презентации.
RetweetБазы данных. Задание FR0 2013-09-30
Минимальная функциональность:
-
Key: nickname
-
Value: ФИО + телефон
-
CRUD:
add(),get(),delete() -
Доступ через консоль или HTTP или TCP
-
В памяти на
ListилиMap -
Персистентное хранение на диске
Зачтено
-
Фёдоров Константин -- +1 бонусный балл
Базы данных. Cassandra 2013-09-30
Лекция "Cassandra" (скачать слайды):
Посмотреть видео на сайте Лекториума.
См. множество ссылок в презентации.
RetweetБазы данных. Курсовой проект 2013-09-16
Для получения зачёта по курсу "Базы данных" необходимо выполнить курсовую работу. В рамках курсовой работы каждая команда (1-3 человека) должна разработать работоспособное Key-Value хранилище данных.
Требования
В первую очередь необходимо создать проект на BitBucket (DVCS Hg) или
GitHub (DVCS Git). Если проект открытый, то нужно прислать мне на
почту ссылку на проект, если проект закрытый -- дать пользователю incubos
права администратора.
Язык программирования -- только Scala или Java.
Обязательны модульные тесты -- ScalaTest или JUnit.
Обязательна система автоматической сборки -- SBT или Maven.
Обязательна базовая документация: README (краткое описание устройства
проекта) и INSTALL (краткое руководство по сборке и запуску проекта, а
также его зависимостям).
Система оценивания
В течение курса будет выдано не менее 6 feature requests (FR). Для каждого FR установлен жёсткий срок, но не менее 2 недель. За каждый FR присуждается 0, 1 или 2 балла (2 балла за особое мастерство и креативность).
Кроме того, существует обязательный FR0. Для тех, кто не успел во время выполнить FR0, FR0 замещается обязательным FR1, а баллы за его выполнение не присуждаются.
Для получения зачёта в конце курса необходимо выполнить обязательные FR, заработать не менее 4 баллов на других FR и написать отчёт.
Проверка FR
FR проверяются каждые выходные, при этом предпочтение отдаётся командам, планомерно двигающимся к цели (равномерные коммиты). Возможно, имеет смысл поддерживать стабильную и нестабильную ветки проекта, чтобы не возникало странностей.
Обратная связь по результатам проверки FR осуществляется в виде issues. Наличие незакрытых issues, относящихся к соответствующему FR, препятствует зачёту по FR.
Отчёт
Отчёт должен содержать 2-10 страниц, включая картинки и не включая титульный лист.
RetweetБазы данных. Введение, Hash and Cache, CAP 2013-09-16
Прочитал 3 лекции на первом занятии курса "Базы данных" в Computer Science Center.
Введение
Посмотреть видео на сайте Лекториума.
Hash and Cache
Посмотреть видео на сайте Лекториума.
Consistency, Availability and Partition Tolerance
Посмотреть видео на сайте Лекториума.
RetweetЛекции по "Базам данных" в Computer Science Center 2013-09-04
В осеннем семестре 2013 года читаю курс "Базы данных" в Computer Science Center. Все материалы будут выкладываться в этот блог.
Мой курс во многом основывается на курсе "Базы данных" 2012 года Ильи Тетерина. Во второй половине курса планирую приглашать моих коллег из Яндекса прочитать по одной лекции про конкретные хранилища данных, экспертами в которых они являются.
RetweetДедуктивная верификация 2013-04-30
В рамках магистерского курса "Методы анализа и обеспечения качества ПО" на кафедре КСПТ прочитал лекцию "Дедуктивная верификация".
RetweetSite launched 2013-04-22
This website uses:
- YAML for metadata
- Markdown for formatting
- Obraz for static generation
- Twitter Bootstrap for layout