Unique Action Counting 2015-08-30
I will describe our approach to unique user action counting using Cassandra. An action is a click, a page view, a phone call or anything similar. Each action connects an object and a user.
A counter for a specific action provides the following methods:
- Connect the user and the object
- Count unique users connected to the object
Sets of users and objects are effectively infinite, but they increase gradually -- new ones appear and former ones don't appear any more. We don't want to run out of space because of storing connections forever, so we need some expiration policy. More about it later.
Data model
Cassandra schema looks like this:
CREATE TABLE IF NOT EXISTS $TABLE(
id varchar,
t varchar,
PRIMARY KEY (id, t))
WITH
compaction = {
'class': 'LeveledCompactionStrategy'
} AND
default_time_to_live = $TTLid is an object id. t is a token identifying user.
As it follows from the schema:
- Token is a clustering key, so only unique tokens are stored
- Tokens are partitioned by objects, so we can issue effective object's unique token counting requests
- LeveledCompactionStrategy tries to store per object rows in a few SSTables to speed up read requests
- We use Cassandra TTL feature to forget about disappeared objects and users
Requests
We have only two kinds of requests.
A request connecting the object and the token:
INSERT INTO $TABLE(id, t) VALUES (:id, :t)A request counting unique tokens associated with the object:
SELECT COUNT(1) as counter FROM $TABLE WHERE id = :id LIMIT $LIMITWe use explicit counter limit to bound the response time in case of extremely (or artificially) popular object.
Both requests are executed with LOCAL_ONE consistency level.
DAO
The DAO uses requests considered before and is based on the official Cassandra Java driver.
Cassandra driver is configured the following way:
Cluster.builder()
.addContactPoints(clusterNodes: _*)
.withCompression(ProtocolOptions.Compression.LZ4)
.withLoadBalancingPolicy(
new TokenAwarePolicy(
new DCAwareRoundRobinPolicy(
localDataCenter,
remoteNodes)))
The implementation uses Session.executeAsync() and is fully asynchronous.
HTTP API
HTTP API is quite simple and delegates to the DAO. Let's HTTP requests.
Get count of tokens connected with object object_id:
$ curl http://myhost/api/v1/counter/object_id
42Connect token token to object object_id and return count of tokens:
$ curl -X PUT -d token http://myhost/api/v1/counter/object_id
43When implementing HTTP API we used Spray.
Benchmarks
We have a two node Cassandra cluster. Each node is a 16 core (with HT) 64 GB SSD machine.
Cassandra keyspace configuration is the following:
replication = {'class': 'NetworkTopologyStrategy', 'DC1': '2'} AND durable_writes = trueHTTP API runs on a 32 core machine.
Test load
The test load depends on two parameters:
- Total number of requests
- Total number of objects
Each test request can be expressed like this:
$ curl -X PUT -d token http://myhost/api/v1/counter/object_idWhere token is a random long value and object_id
is an int value between 0 and total number of objects
chosen using Gaussian distribution to model hot (popular) objects.
100 objects and 10M tokens
Cassandra nodes' CPUs get fully saturated at 700 rps load. The stable load area:
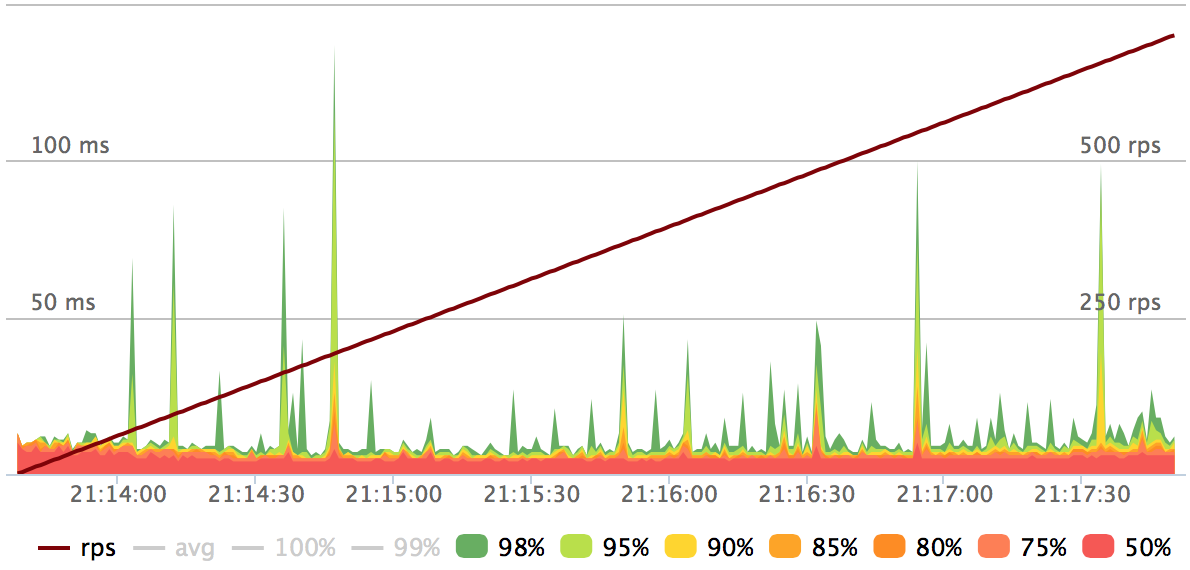
Some numbers:
- 50% of requests < 5 ms
- 99.8% of requests < 50 ms
- 99.95% of requests < 100 ms
1K objects and 10M tokens
Cassandra nodes' CPUs get fully saturated at 2.5 Krps load. The stable load area:
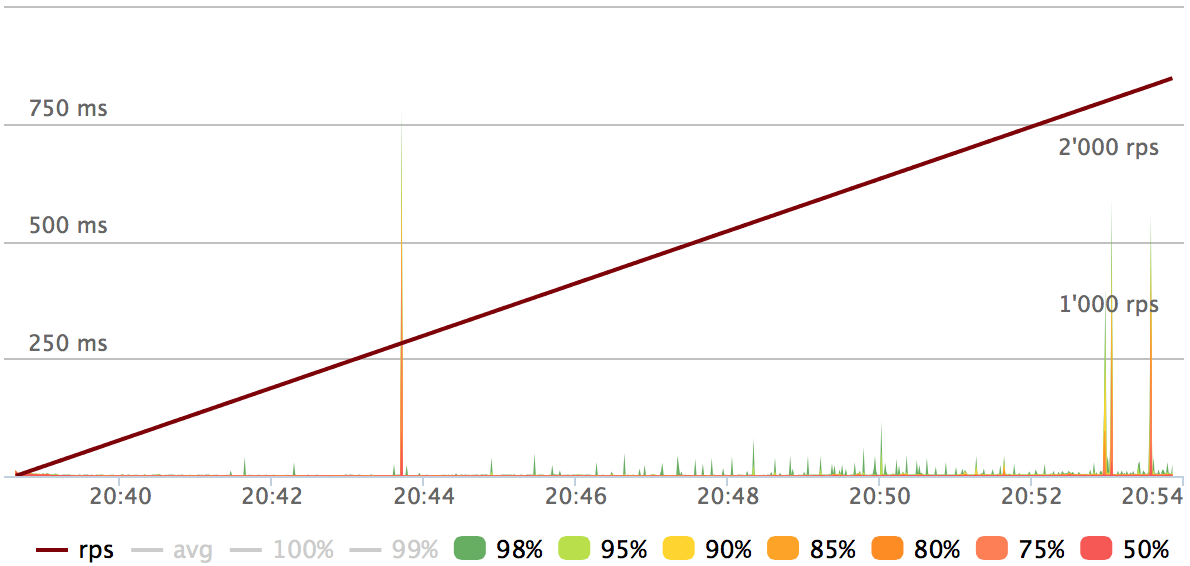
Some numbers:
- 50% of requests < 2 ms
- 99.5% of requests < 50 ms
- 99.68% of requests < 100 ms
- 99.84% of requests < 300 ms
- 99.94% of requests < 500 ms
Conclusion
We considered unique action counters on top of Cassandra storage. This implementation (with some minor changes and caching added) is used in all the user facing counters in Yandex.Auto, Yandex.Realty and Yandex.Rabota.
Next time we might consider:
- Probabilistic persistent caching using Cassandra static columns
- Non unique counters (clickers) and rate limiters based on Cassandra